9 Graphing Relationships
So far we have dealt with data obtained from one variable (either categorical or quantitative) and learned how to describe the distribution of the variable using the appropriate visual displays and numerical measures. In this section, examining relationships, we will look at two variables at a time and, as the title suggests, explore the relationship between them using (as before) visual displays and numerical summaries.
While it is fundamentally important to know how to describe the distribution of a single variable, most studies (including yours) pose research questions that involve exploring the relationship between two variables.
Here are a few examples of such research questions with the two variables highlighted:
Examples:
- Is there a relationship between gender and test scores on a particular standardized test?
Other ways of phrasing the same research question:
- Is performance on the test related to gender?
- Is there a gender effect on test scores?
- Are there differences in test scores between males and females?
Is there a relationship between the type of light a baby sleeps with (no light, night-light, lamp) and whether the child develops nearsightedness?
Are the smoking habits of a person (yes, no) related to the person’s gender?
How well can we predict a student’s freshman year GPA from his/her SAT score?
In most analyses involving two variables, each of the variables has a role. We distinguish between:
- the response variable (also known as the dependent variable (DV), or outcome)
- the explanatory variable (also known as the independent variable (IV), or the predictor)
At this point, we will be asking you to “impose” a causal model on your research question, despite the fact that you will not be able to directly evaluate a causal relationship. This video defines the two types of variables you will be identifying and shows you how this decision will guide the kinds of graphing you do and the kind of statistical tests that you will ultimately use. Please watch Chapter 09 video.
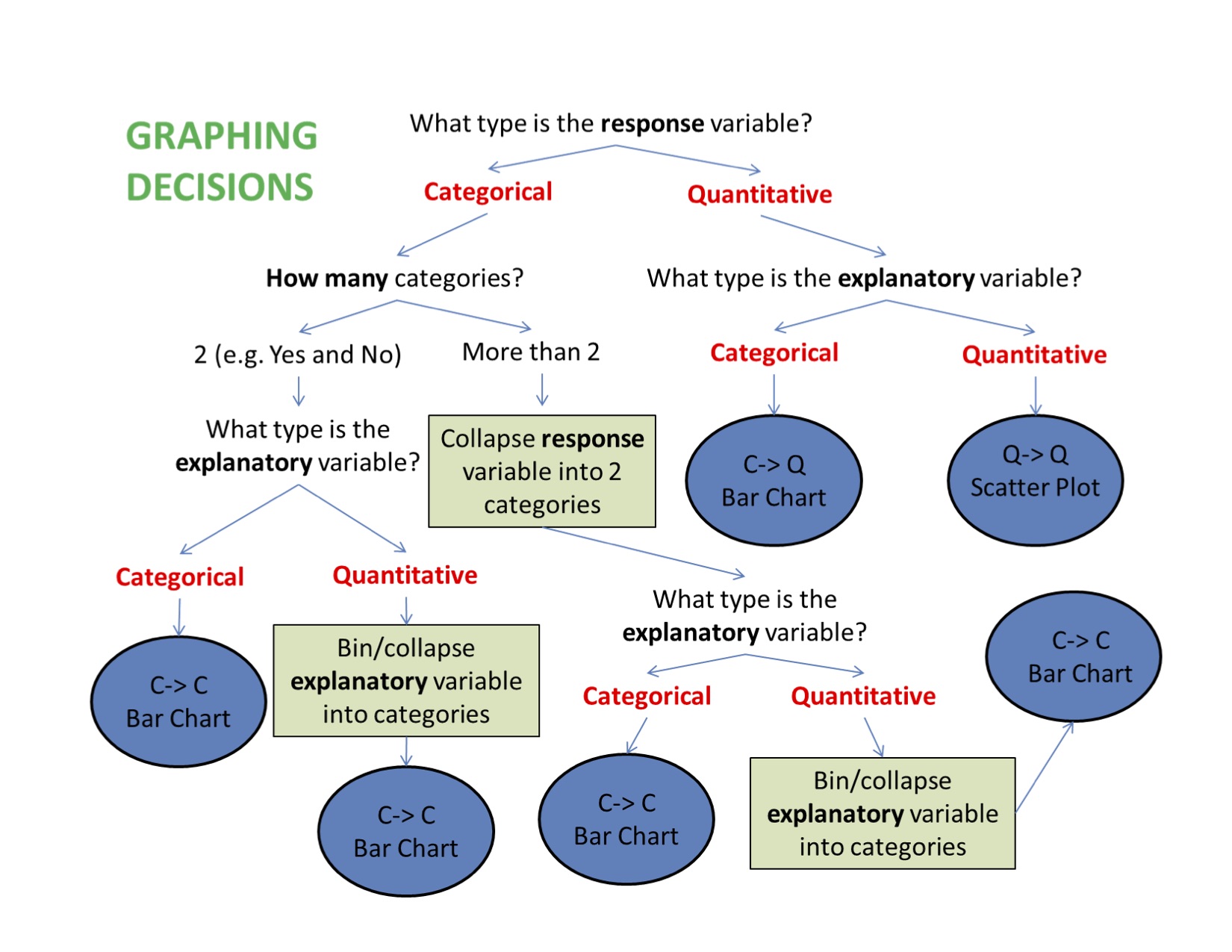
When graphing your data, it is important that each graph provides clear and accurate summaries of the data that do not mislead.
9.1 Bivariate Graphing
(C \(\rightarrow\) C) Prevalence of Nicotine Dependence (C) by Depression Status (C) (among current, daily, young adult smokers \(\rightarrow\) values stored in nesarc created in chapter 7)
library(ggplot2)
library(PDS)
ggplot(data = nesarc, aes(x = MajorDepression, fill = TobaccoDependence)) +
geom_bar(position = "fill") +
theme_bw() +
labs(x = "", y = "Fraction",
title = "Fraction of young adult daily smokers\nwith and without nicotine addiction\nby depression status") +
scale_fill_manual(values = c("green", "red"), name = "Tobacco Addiction Status") +
guides(fill = guide_legend(reverse = TRUE))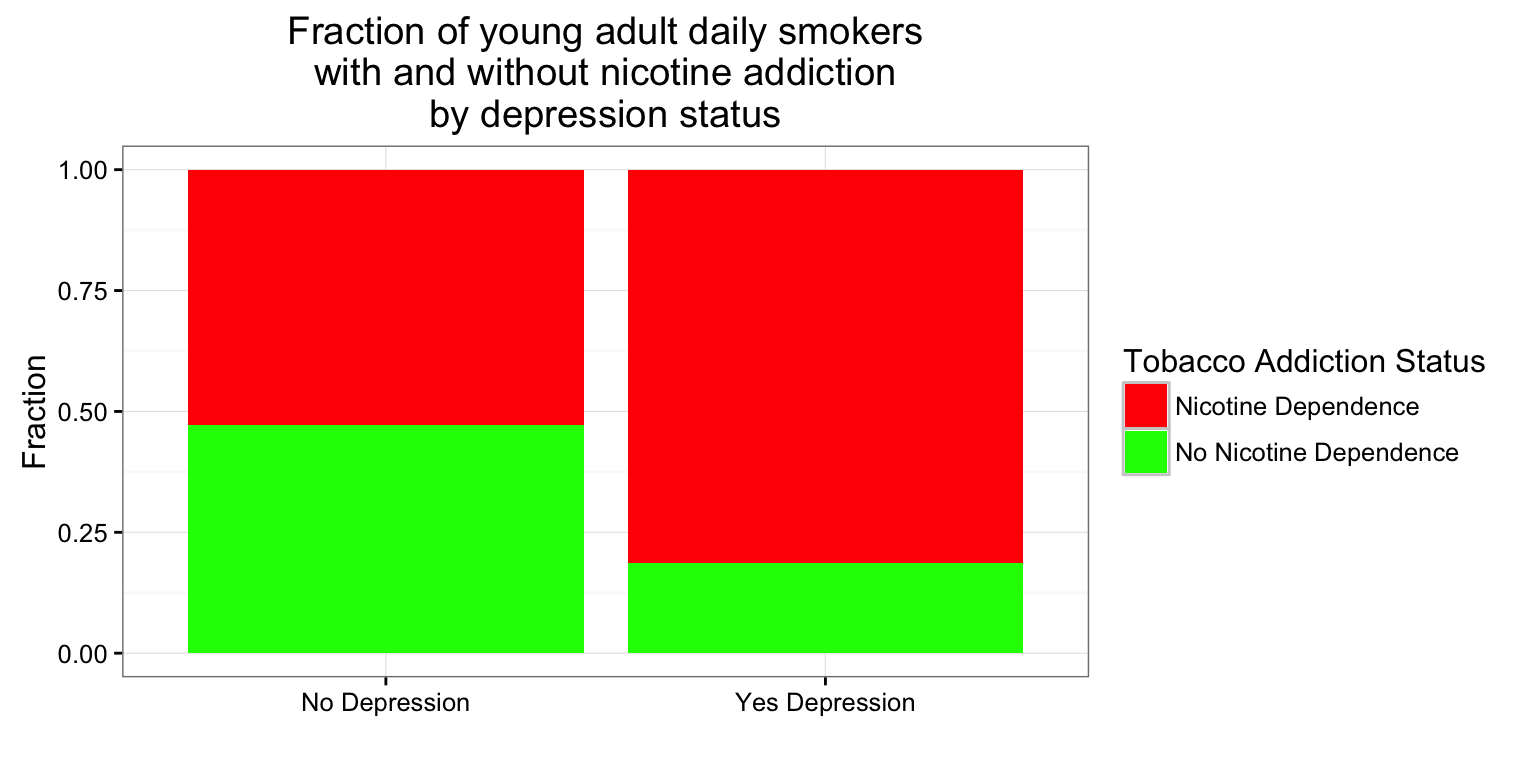
Mosaic Plots
library(vcd)
mosaic(~TobaccoDependence + MajorDepression ,data = nesarc, shade = TRUE)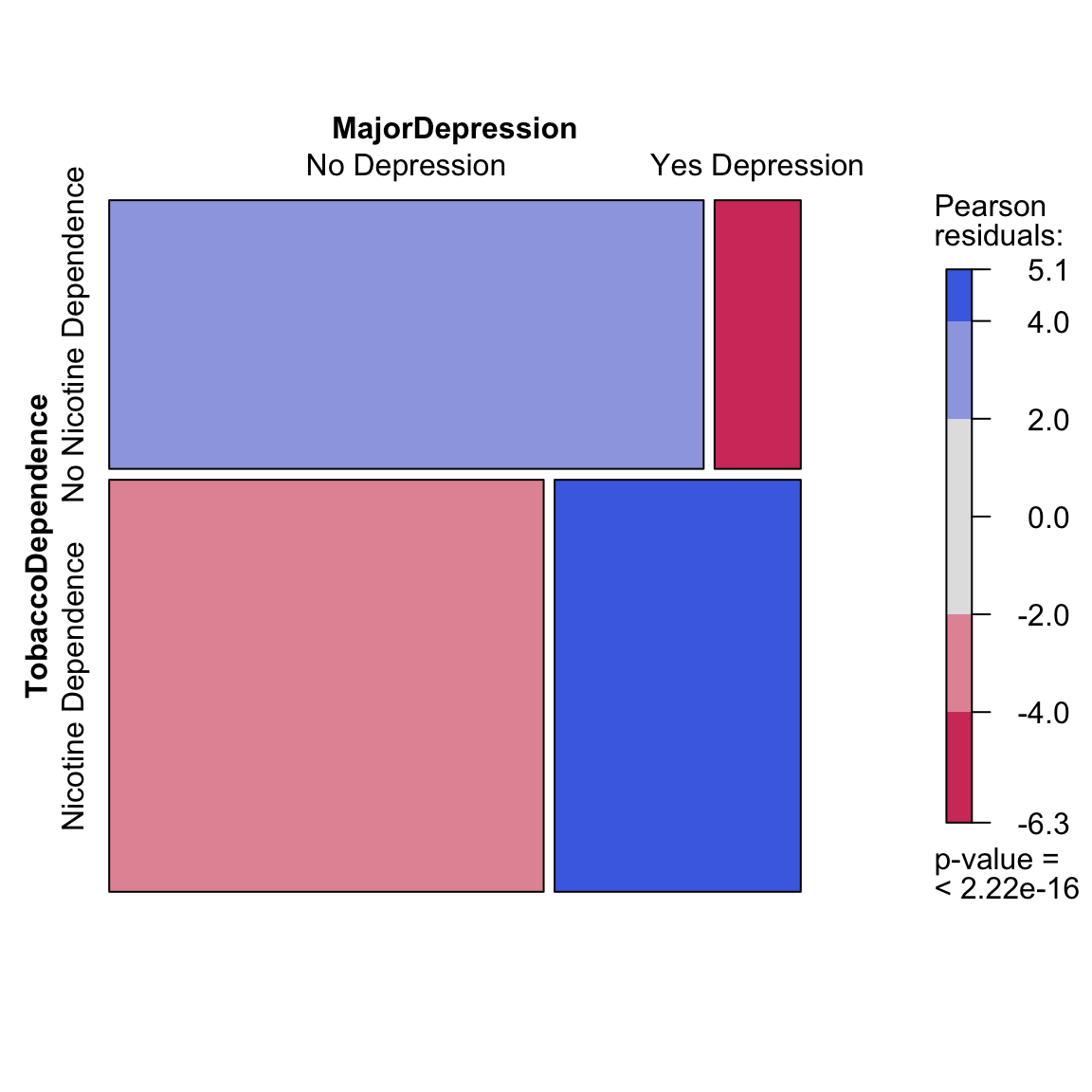
(\(C \rightarrow Q\)) Boxplots and Violin plots
ggplot(data = frustration, aes(x = Major, y = Frustration.Score)) +
geom_boxplot() +
theme_bw() +
labs(x = "", y = "Frustration Score", title = "Frustration Score by\n Academic Major")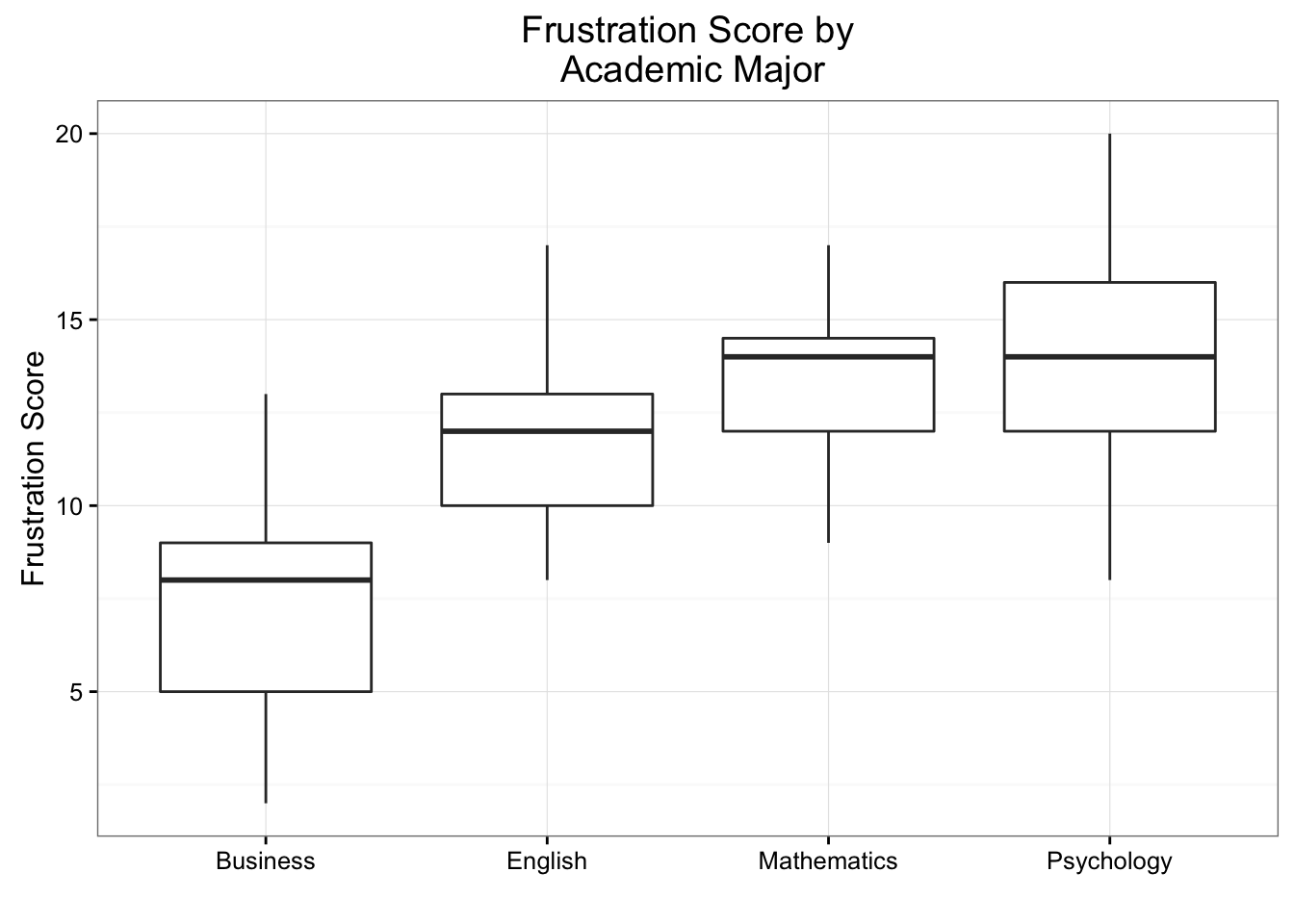
# Violin plots
ggplot(data = frustration, aes(x = Major, y = Frustration.Score)) +
geom_violin() +
theme_bw() +
labs(x = "", y = "Frustration Score", title = "Frustration Score by\n Academic Major")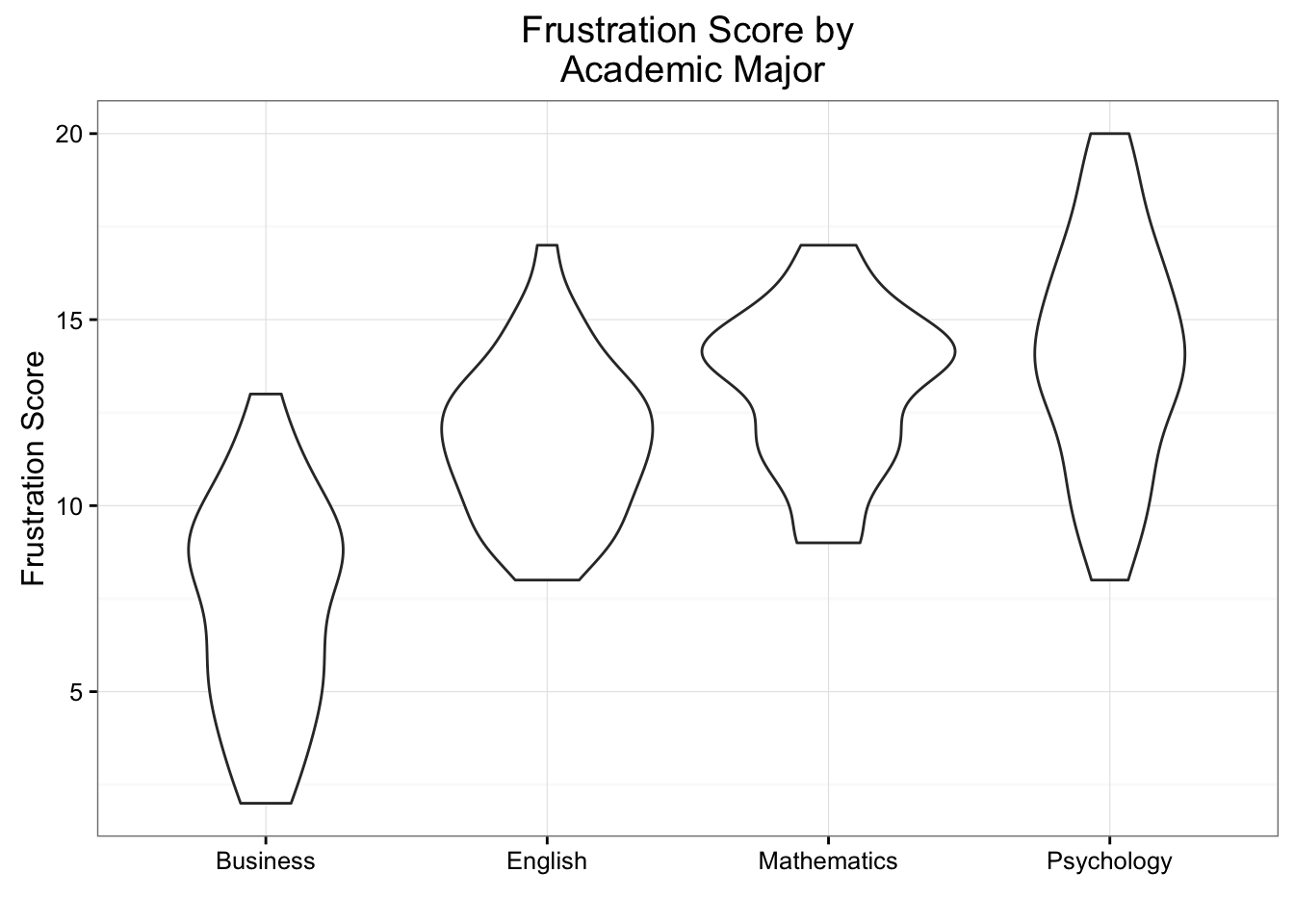
(Q \(\rightarrow\) Q) Scatter plots
library(PASWR2)
ggplot(data = GRADES, aes(x = sat, y = gpa)) +
geom_point(color = "lightblue") +
theme_bw() +
labs(x = "SAT score", y = "First semester college Grade Point Average") +
geom_smooth(method = "lm")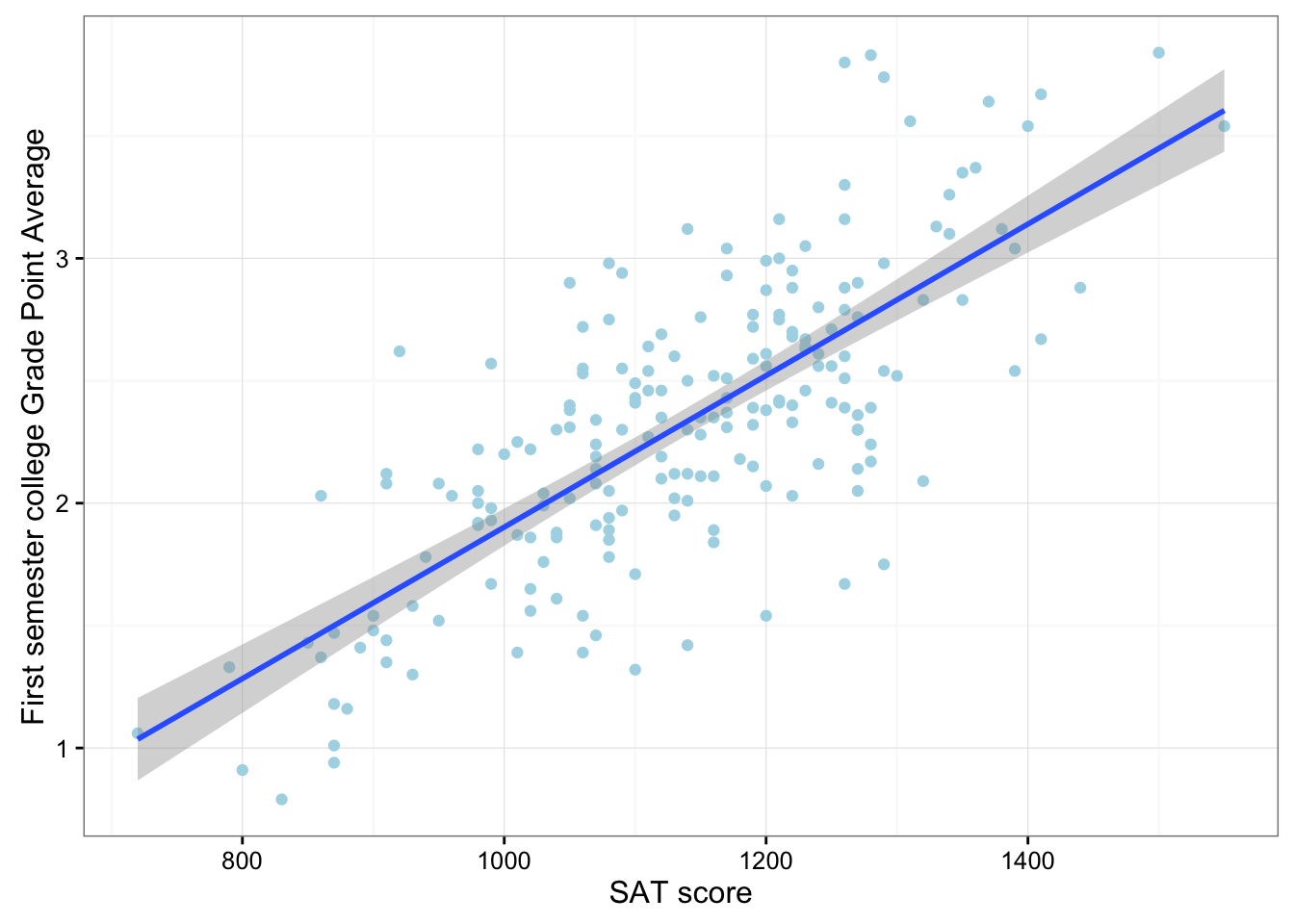
(\(Q \rightarrow C\)) Scatter plot for logistic regression
library(ISLR)
library(ggplot2)
Default$defaultN <- ifelse(Default$default == "No", 0, 1)
Default$studentN <- ifelse(Default$student =="No", 0, 1)
ggplot(data = Default, aes(x = balance, y = defaultN)) +
geom_point(alpha = 0.5) +
theme_bw() +
stat_smooth(method = "glm", method.args = list(family = "binomial")) +
labs(y = "Probability of Default")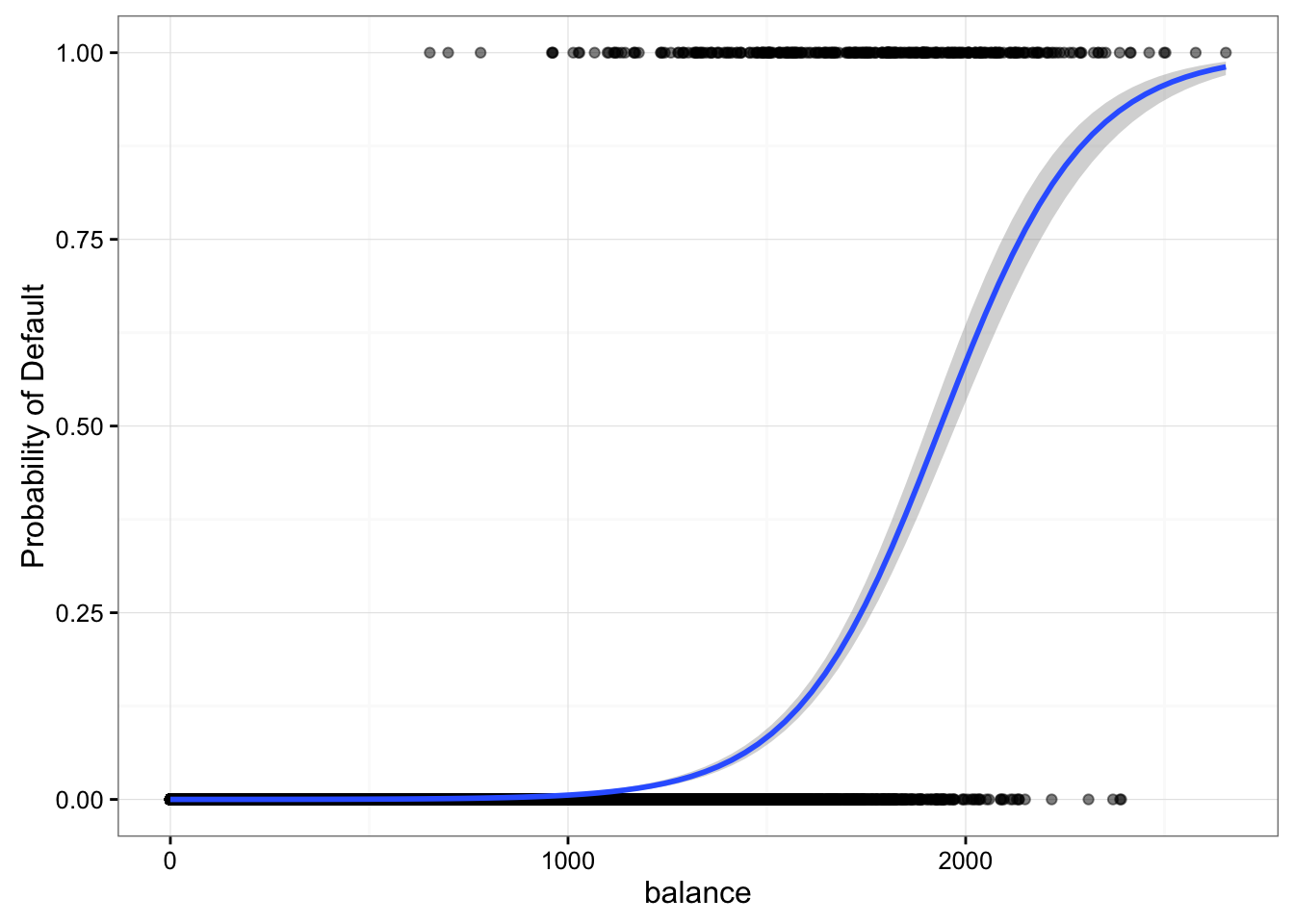
9.2 Multivariate Graphing
ggplot(data = nesarc, aes(x = MajorDepression, fill = TobaccoDependence)) +
geom_bar(position = "fill") +
theme_bw() +
labs(x = "", y = "Fraction", title = "Fraction of young adult daily smokers\nwith and without nicotine addiction\nby depression status") +
scale_fill_manual(values = c("green", "red"), name = "Tobacco Addiction Status") +
facet_grid(Sex ~ .) +
guides(fill = guide_legend(reverse = TRUE))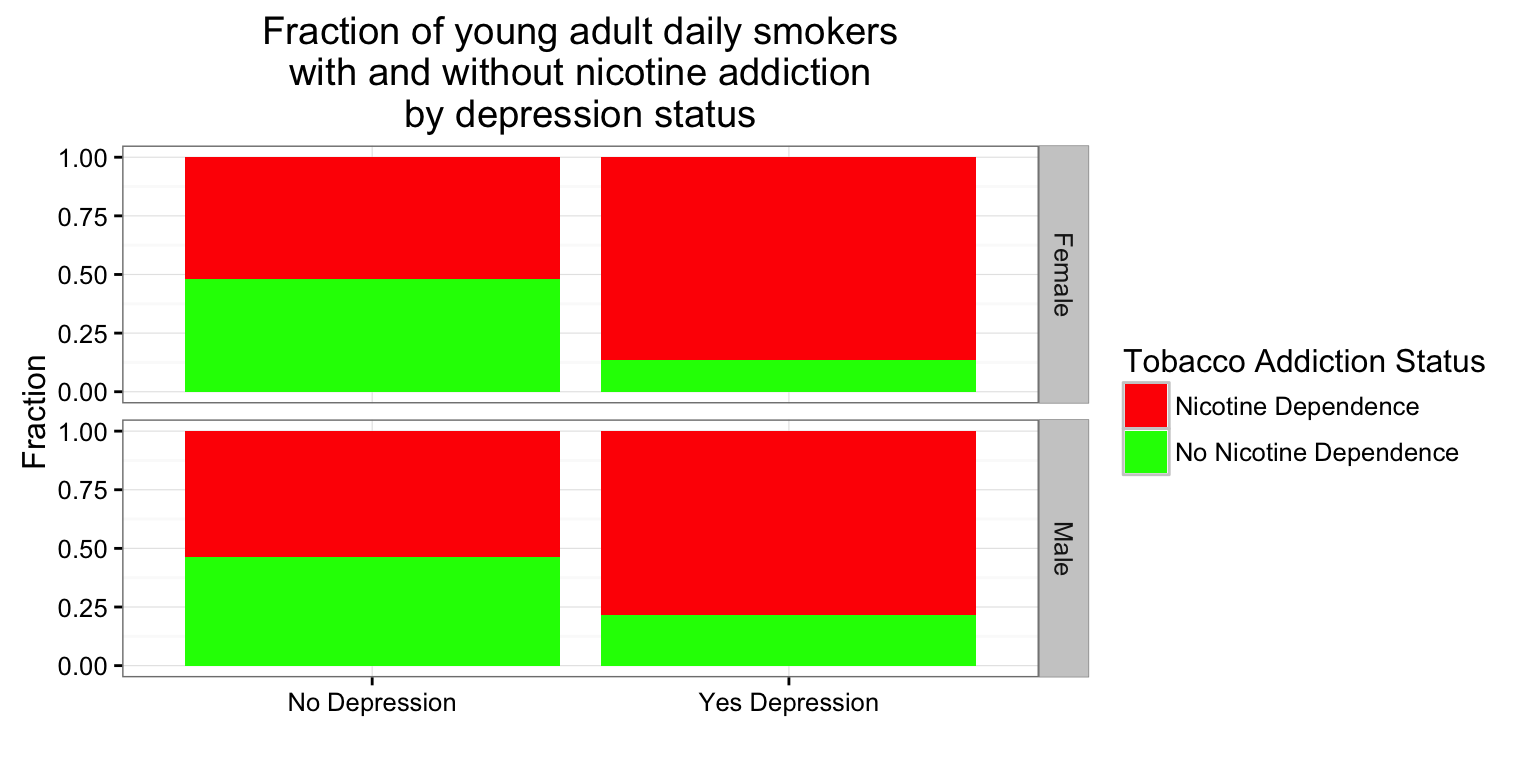
Graphs that seem to provide important information can in fact be erroneous. Please watch the COMMON GRAPHING MISTAKES VIDEO (3:35).
Bivariate Graphing Assignment
Post a graph showing the association between your explanatory and response variables (bivariate graph) on your private GitHub repository. Include a second graph of your bivariate graph by a third variable (multivariate graph). Write a few sentences describing what your graphs show.