library(DT)datatable(AD[, -1], rownames =FALSE,caption ='Table 1: This is a simple caption for the table.')
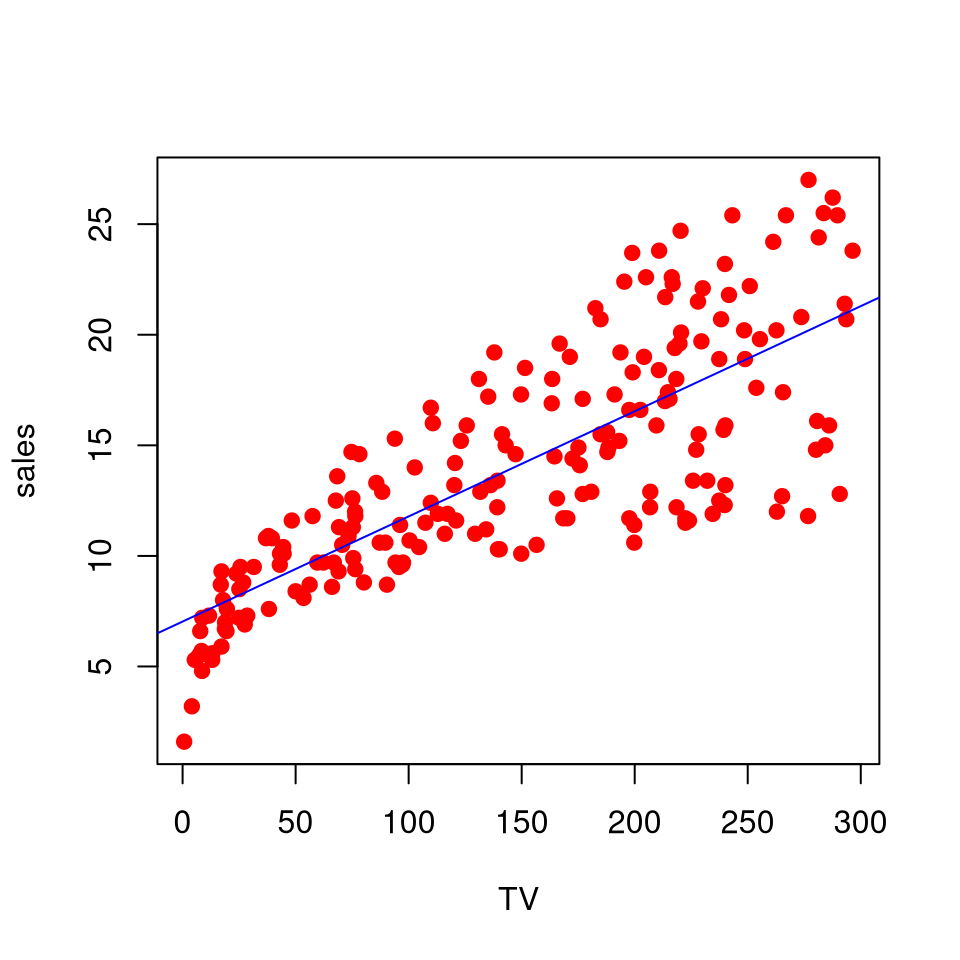
Base R Graph
plot(sales ~ TV, data = AD, col ="red", pch =19)mod1 <-lm(sales ~ TV, data = AD)abline(mod1, col ="blue")
Figure 1: Base R scatterplot of sales versus TV
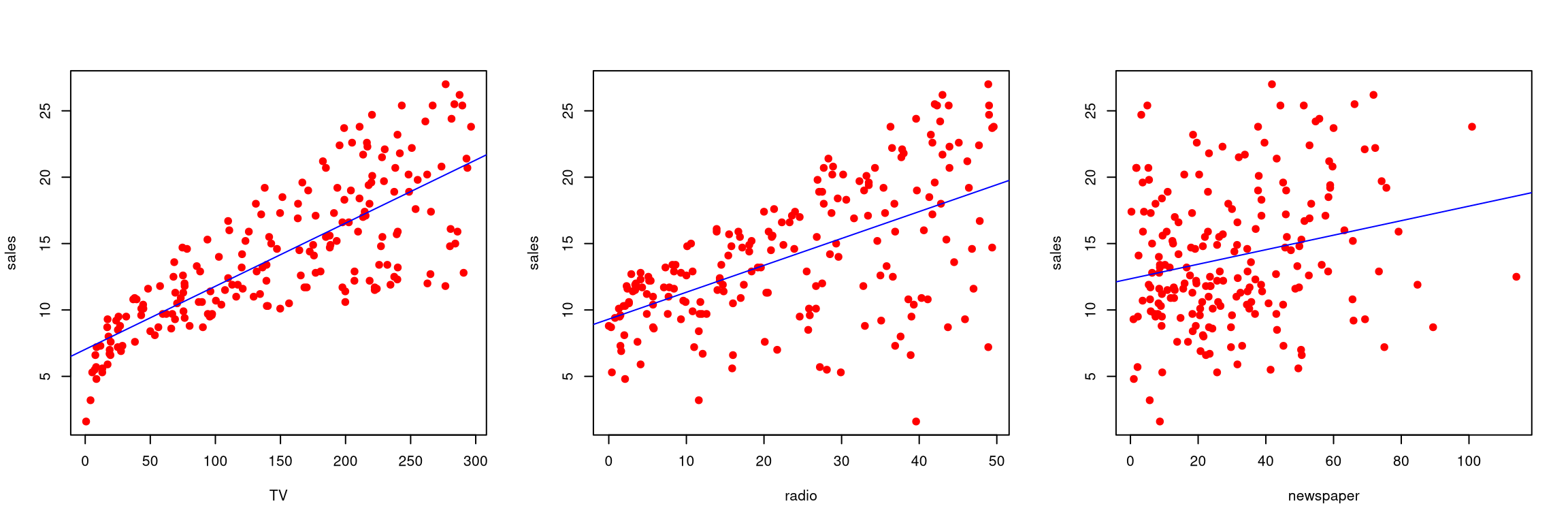
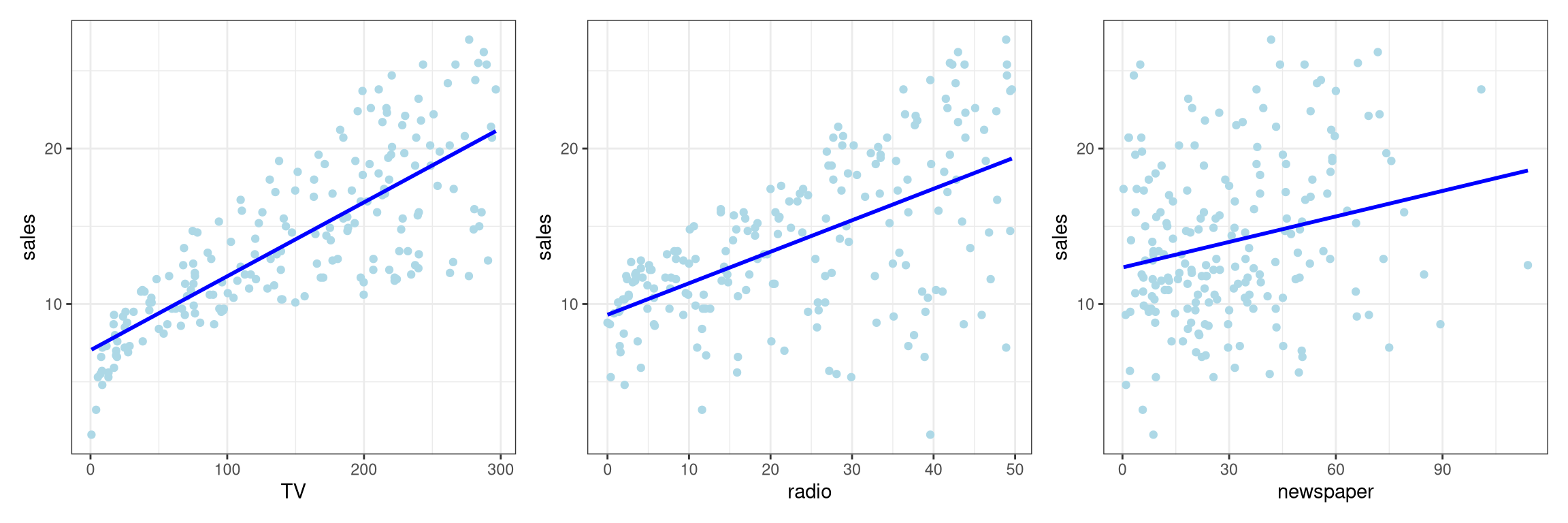
par(mfrow =c(1, 3))plot(sales ~ TV, data = AD, col ="red", pch =19)mod1 <-lm(sales ~ TV, data = AD)abline(mod1, col ="blue")plot(sales ~ radio, data = AD, col ="red", pch =19)mod2 <-lm(sales ~ radio, data = AD)abline(mod2, col ="blue")plot(sales ~ newspaper, data = AD, col ="red", pch =19)mod3 <-lm(sales ~ newspaper, data = AD)abline(mod3, col ="blue")par(mfrow=c(1, 1))
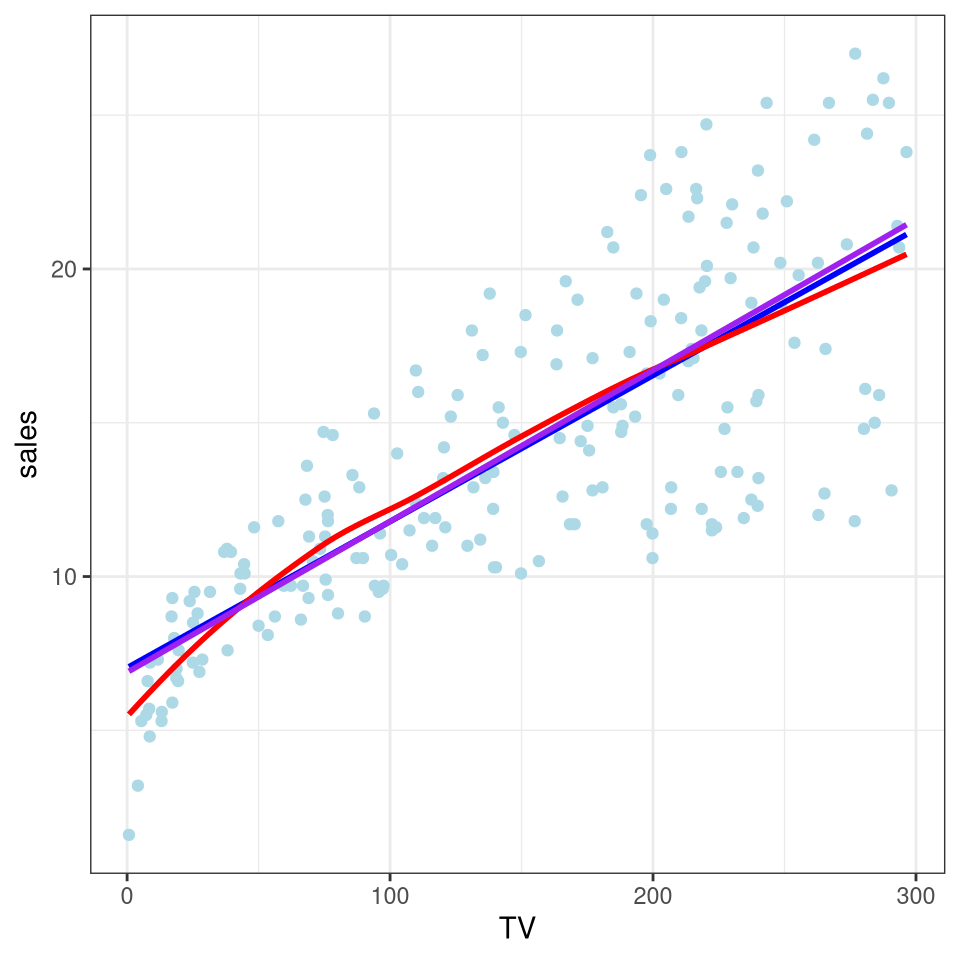
library(ggplot2)library(MASS)p <-ggplot(data = AD, aes(x = TV, y = sales)) +geom_point(color ="lightblue") +geom_smooth(method ="lm", se =FALSE, color ="blue") +geom_smooth(method ="loess", color ="red", se =FALSE) +geom_smooth(method ="rlm", color ="purple", se =FALSE) +theme_bw()p
Figure 3: ggplot graph with three superimposed lines
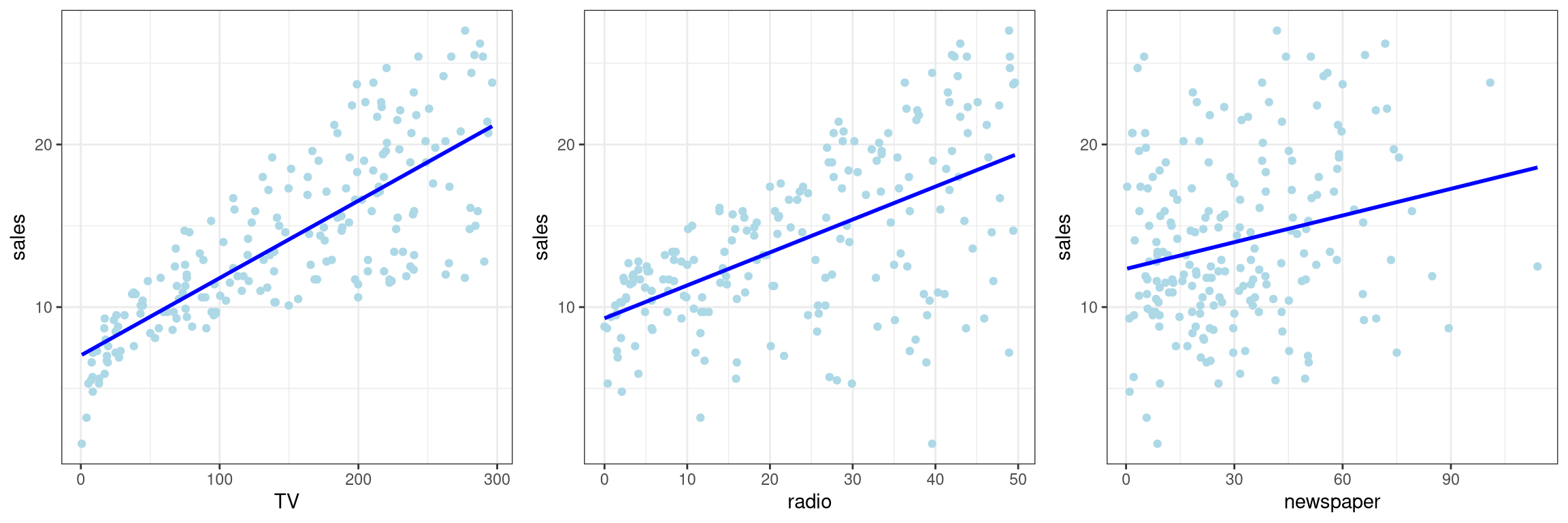
library(gridExtra)p1 <-ggplot(data = AD, aes(x = TV, y = sales)) +geom_point(color ="lightblue") +geom_smooth(method ="lm", se =FALSE, color ="blue") +theme_bw()p2 <-ggplot(data = AD, aes(x = radio, y = sales)) +geom_point(color ="lightblue") +geom_smooth(method ="lm", se =FALSE, color ="blue") +theme_bw()p3 <-ggplot(data = AD, aes(x = newspaper, y = sales)) +geom_point(color ="lightblue") +geom_smooth(method ="lm", se =FALSE, color ="blue") +theme_bw()grid.arrange(p1, p2, p3, ncol =3)
Figure 4: Using grid.arrange() with ggplot
library(patchwork)p1 + p2 + p3
Using patchwork with ggplot
Using ggvis
library(ggvis)AD %>%ggvis(x =~TV, y =~sales) %>%layer_points() %>%layer_model_predictions(model ="lm", se =FALSE) %>%layer_model_predictions(model ="MASS::rlm", se =FALSE, stroke :="blue") %>%layer_smooths(stroke:="red", se =FALSE)
Using plotly
library(plotly)p11 <-ggplotly(p)p11
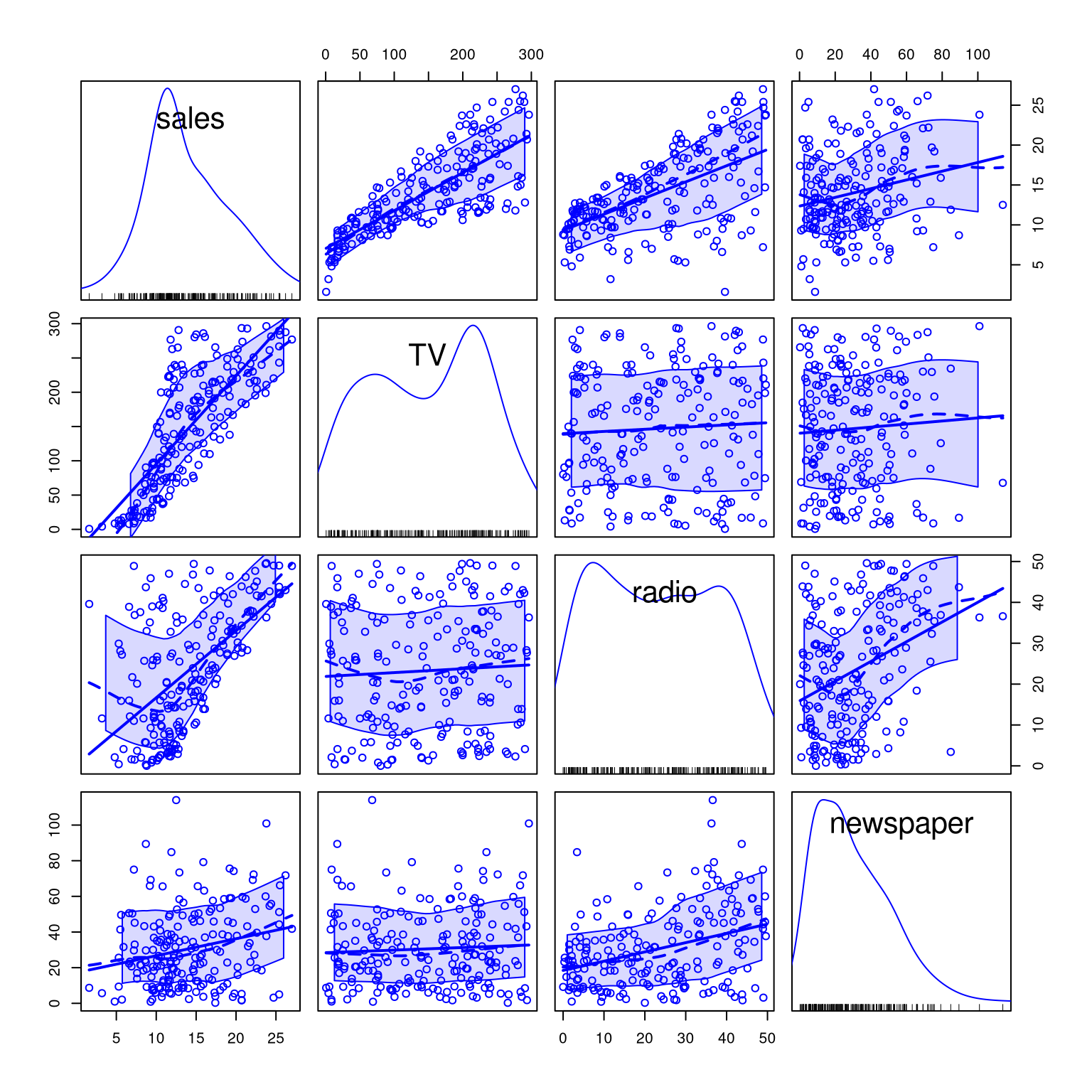
Scatterplot Matrices
library(car)scatterplotMatrix(~ sales + TV + radio + newspaper, data = AD)
Basic Regression
Recall mod1
mod1 <-lm(sales ~ TV, data = AD)summary(mod1)
Call:
lm(formula = sales ~ TV, data = AD)
Residuals:
Min 1Q Median 3Q Max
-8.3860 -1.9545 -0.1913 2.0671 7.2124
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.032594 0.457843 15.36 <2e-16 ***
TV 0.047537 0.002691 17.67 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.259 on 198 degrees of freedom
Multiple R-squared: 0.6119, Adjusted R-squared: 0.6099
F-statistic: 312.1 on 1 and 198 DF, p-value: < 2.2e-16
Estimation of the Mean Response for New Values \(X_h\)
Not only is it desirable to create confidence intervals on the parameters of the regression models, bit it is also common to estimate the mean response \(\left(E(Y_h)\right)\) for a particular set of \(\mathbf{X}\) values.
\[\hat{Y_h} \sim N(Y_h = X_h\beta, \sigma^2\mathbf{X_h}(\mathbf{X'X})^{-1}\mathbf{X_h'})\] For a vector of given values \((\mathbf{X_h})\), a \((1 - \alpha)\cdot 100\%\) confidence interval for the mean response \(E(Y_h)\) is
\[CI_{1-\alpha}\left[E(Y_h)\right] = \left[\hat{Y_h} - t_{1 - \alpha/2;n - p - 1}\cdot s_{\hat{Y_h}}, \hat{Y_h} + t_{1 - \alpha/2;n - p - 1}\cdot s_{\hat{Y_h}} \right]\] The function predict() applied to a linear model object will compute \(\hat{Y_h}\) and \(s_{\hat{Y_h}}\) for a given \(\mathbf{X}_h\). R output has \(\hat{Y_h}\) labeled fit and \(s_{\hat{Y_h}}\) labeled se.fit.
(Intercept) TV
(Intercept) 0.209620158 -1.064495e-03
TV -0.001064495 7.239367e-06
Example Use the GRADES data set and model gpa as a function of sat. Compute the expected GPA (gpa) for an SAT score (sat) of 1300. Construct a 90% confidence interval for the mean GPA for students scoring 1300 on the SAT.
library(PASWR2)mod.lm <-lm(gpa ~ sat, data = GRADES)summary(mod.lm)
Call:
lm(formula = gpa ~ sat, data = GRADES)
Residuals:
Min 1Q Median 3Q Max
-1.04954 -0.25960 -0.00655 0.26044 1.09328
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.1920638 0.2224502 -5.359 2.32e-07 ***
sat 0.0030943 0.0001945 15.912 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3994 on 198 degrees of freedom
Multiple R-squared: 0.5612, Adjusted R-squared: 0.5589
F-statistic: 253.2 on 1 and 198 DF, p-value: < 2.2e-16
Call:
lm(formula = sales ~ TV + radio + newspaper, data = AD)
Residuals:
Min 1Q Median 3Q Max
-8.8277 -0.8908 0.2418 1.1893 2.8292
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.938889 0.311908 9.422 <2e-16 ***
TV 0.045765 0.001395 32.809 <2e-16 ***
radio 0.188530 0.008611 21.893 <2e-16 ***
newspaper -0.001037 0.005871 -0.177 0.86
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.686 on 196 degrees of freedom
Multiple R-squared: 0.8972, Adjusted R-squared: 0.8956
F-statistic: 570.3 on 3 and 196 DF, p-value: < 2.2e-16
summary(mod3)$fstatistic
value numdf dendf
570.2707 3.0000 196.0000
Suppose we would like to test whether \(\beta_2 = \beta_3 = 0\). The reduced model with \(\beta_2 = \beta_3 = 0\) is mod1 while the full model is mod3.
summary(mod3)
Call:
lm(formula = sales ~ TV + radio + newspaper, data = AD)
Residuals:
Min 1Q Median 3Q Max
-8.8277 -0.8908 0.2418 1.1893 2.8292
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.938889 0.311908 9.422 <2e-16 ***
TV 0.045765 0.001395 32.809 <2e-16 ***
radio 0.188530 0.008611 21.893 <2e-16 ***
newspaper -0.001037 0.005871 -0.177 0.86
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.686 on 196 degrees of freedom
Multiple R-squared: 0.8972, Adjusted R-squared: 0.8956
F-statistic: 570.3 on 3 and 196 DF, p-value: < 2.2e-16
anova(mod1, mod3)
Analysis of Variance Table
Model 1: sales ~ TV
Model 2: sales ~ TV + radio + newspaper
Res.Df RSS Df Sum of Sq F Pr(>F)
1 198 2102.53
2 196 556.83 2 1545.7 272.04 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Variable Selection
Forward selection
mod.fs <-lm(sales ~1, data = AD)SCOPE <- (~ TV + radio + newspaper)add1(mod.fs, scope = SCOPE, test ="F")
Single term additions
Model:
sales ~ 1
Df Sum of Sq RSS AIC F value Pr(>F)
<none> 5417.1 661.80
TV 1 3314.6 2102.5 474.52 312.145 < 2.2e-16 ***
radio 1 1798.7 3618.5 583.10 98.422 < 2.2e-16 ***
newspaper 1 282.3 5134.8 653.10 10.887 0.001148 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
mod.fs <-update(mod.fs, .~. + TV)add1(mod.fs, scope = SCOPE, test ="F")
Single term additions
Model:
sales ~ TV
Df Sum of Sq RSS AIC F value Pr(>F)
<none> 2102.53 474.52
radio 1 1545.62 556.91 210.82 546.74 < 2.2e-16 ***
newspaper 1 183.97 1918.56 458.20 18.89 2.217e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
mod.fs <-update(mod.fs, .~. + radio)add1(mod.fs, scope = SCOPE, test ="F")
Single term additions
Model:
sales ~ TV + radio
Df Sum of Sq RSS AIC F value Pr(>F)
<none> 556.91 210.82
newspaper 1 0.088717 556.83 212.79 0.0312 0.8599
summary(mod.fs)
Call:
lm(formula = sales ~ TV + radio, data = AD)
Residuals:
Min 1Q Median 3Q Max
-8.7977 -0.8752 0.2422 1.1708 2.8328
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.92110 0.29449 9.919 <2e-16 ***
TV 0.04575 0.00139 32.909 <2e-16 ***
radio 0.18799 0.00804 23.382 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.681 on 197 degrees of freedom
Multiple R-squared: 0.8972, Adjusted R-squared: 0.8962
F-statistic: 859.6 on 2 and 197 DF, p-value: < 2.2e-16
Using stepAIC
stepAIC(lm(sales ~1, data = AD), scope = (~TV + radio + newspaper), direction ="forward", test ="F")
Start: AIC=661.8
sales ~ 1
Df Sum of Sq RSS AIC F Value Pr(F)
+ TV 1 3314.6 2102.5 474.52 312.145 < 2.2e-16 ***
+ radio 1 1798.7 3618.5 583.10 98.422 < 2.2e-16 ***
+ newspaper 1 282.3 5134.8 653.10 10.887 0.001148 **
<none> 5417.1 661.80
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Step: AIC=474.52
sales ~ TV
Df Sum of Sq RSS AIC F Value Pr(F)
+ radio 1 1545.62 556.91 210.82 546.74 < 2.2e-16 ***
+ newspaper 1 183.97 1918.56 458.20 18.89 2.217e-05 ***
<none> 2102.53 474.52
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Step: AIC=210.82
sales ~ TV + radio
Df Sum of Sq RSS AIC F Value Pr(F)
<none> 556.91 210.82
+ newspaper 1 0.088717 556.83 212.79 0.031228 0.8599
Call:
lm(formula = sales ~ TV + radio, data = AD)
Coefficients:
(Intercept) TV radio
2.92110 0.04575 0.18799
# Ornull <-lm(sales ~1, data = AD)full <-lm(sales ~ ., data = AD)stepAIC(null, scope =list(lower = null, upper = full), direction ="forward", test ="F")
Start: AIC=661.8
sales ~ 1
Df Sum of Sq RSS AIC F Value Pr(F)
+ TV 1 3314.6 2102.5 474.52 312.145 < 2.2e-16 ***
+ radio 1 1798.7 3618.5 583.10 98.422 < 2.2e-16 ***
+ newspaper 1 282.3 5134.8 653.10 10.887 0.001148 **
<none> 5417.1 661.80
+ X 1 14.4 5402.7 663.27 0.529 0.467917
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Step: AIC=474.52
sales ~ TV
Df Sum of Sq RSS AIC F Value Pr(F)
+ radio 1 1545.62 556.91 210.82 546.74 < 2.2e-16 ***
+ newspaper 1 183.97 1918.56 458.20 18.89 2.217e-05 ***
+ X 1 23.23 2079.30 474.29 2.20 0.1395
<none> 2102.53 474.52
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Step: AIC=210.82
sales ~ TV + radio
Df Sum of Sq RSS AIC F Value Pr(F)
<none> 556.91 210.82
+ X 1 0.181080 556.73 212.75 0.063750 0.8009
+ newspaper 1 0.088717 556.83 212.79 0.031228 0.8599
Call:
lm(formula = sales ~ TV + radio, data = AD)
Coefficients:
(Intercept) TV radio
2.92110 0.04575 0.18799
Backward elimination
mod.be <-lm(sales ~ TV + radio + newspaper, data = AD)drop1(mod.be, test ="F")
Single term deletions
Model:
sales ~ TV + radio + newspaper
Df Sum of Sq RSS AIC F value Pr(>F)
<none> 556.8 212.79
TV 1 3058.01 3614.8 584.90 1076.4058 <2e-16 ***
radio 1 1361.74 1918.6 458.20 479.3252 <2e-16 ***
newspaper 1 0.09 556.9 210.82 0.0312 0.8599
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
mod.be <-update(mod.be, .~. - newspaper)drop1(mod.be, test ="F")
Single term deletions
Model:
sales ~ TV + radio
Df Sum of Sq RSS AIC F value Pr(>F)
<none> 556.9 210.82
TV 1 3061.6 3618.5 583.10 1082.98 < 2.2e-16 ***
radio 1 1545.6 2102.5 474.52 546.74 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
summary(mod.be)
Call:
lm(formula = sales ~ TV + radio, data = AD)
Residuals:
Min 1Q Median 3Q Max
-8.7977 -0.8752 0.2422 1.1708 2.8328
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.92110 0.29449 9.919 <2e-16 ***
TV 0.04575 0.00139 32.909 <2e-16 ***
radio 0.18799 0.00804 23.382 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.681 on 197 degrees of freedom
Multiple R-squared: 0.8972, Adjusted R-squared: 0.8962
F-statistic: 859.6 on 2 and 197 DF, p-value: < 2.2e-16
Using stepAIC
stepAIC(lm(sales ~ TV + radio + newspaper, data = AD), scope = (~TV + radio + newspaper), direction ="backward", test ="F")
Start: AIC=212.79
sales ~ TV + radio + newspaper
Df Sum of Sq RSS AIC F Value Pr(F)
- newspaper 1 0.09 556.9 210.82 0.03 0.8599
<none> 556.8 212.79
- radio 1 1361.74 1918.6 458.20 479.33 <2e-16 ***
- TV 1 3058.01 3614.8 584.90 1076.41 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Step: AIC=210.82
sales ~ TV + radio
Df Sum of Sq RSS AIC F Value Pr(F)
<none> 556.9 210.82
- radio 1 1545.6 2102.5 474.52 546.74 < 2.2e-16 ***
- TV 1 3061.6 3618.5 583.10 1082.98 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Call:
lm(formula = sales ~ TV + radio, data = AD)
Coefficients:
(Intercept) TV radio
2.92110 0.04575 0.18799
# OrstepAIC(full, scope =list(lower = null, upper = full), direction ="backward", test ="F")
Start: AIC=214.71
sales ~ X + TV + radio + newspaper
Df Sum of Sq RSS AIC F Value Pr(F)
- newspaper 1 0.13 556.7 212.75 0.04 0.8342
- X 1 0.22 556.8 212.79 0.08 0.7827
<none> 556.6 214.71
- radio 1 1354.48 1911.1 459.42 474.52 <2e-16 ***
- TV 1 3056.91 3613.5 586.82 1070.95 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Step: AIC=212.75
sales ~ X + TV + radio
Df Sum of Sq RSS AIC F Value Pr(F)
- X 1 0.18 556.9 210.82 0.06 0.8009
<none> 556.7 212.75
- radio 1 1522.57 2079.3 474.29 536.03 <2e-16 ***
- TV 1 3060.94 3617.7 585.05 1077.61 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Step: AIC=210.82
sales ~ TV + radio
Df Sum of Sq RSS AIC F Value Pr(F)
<none> 556.9 210.82
- radio 1 1545.6 2102.5 474.52 546.74 < 2.2e-16 ***
- TV 1 3061.6 3618.5 583.10 1082.98 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Call:
lm(formula = sales ~ TV + radio, data = AD)
Coefficients:
(Intercept) TV radio
2.92110 0.04575 0.18799
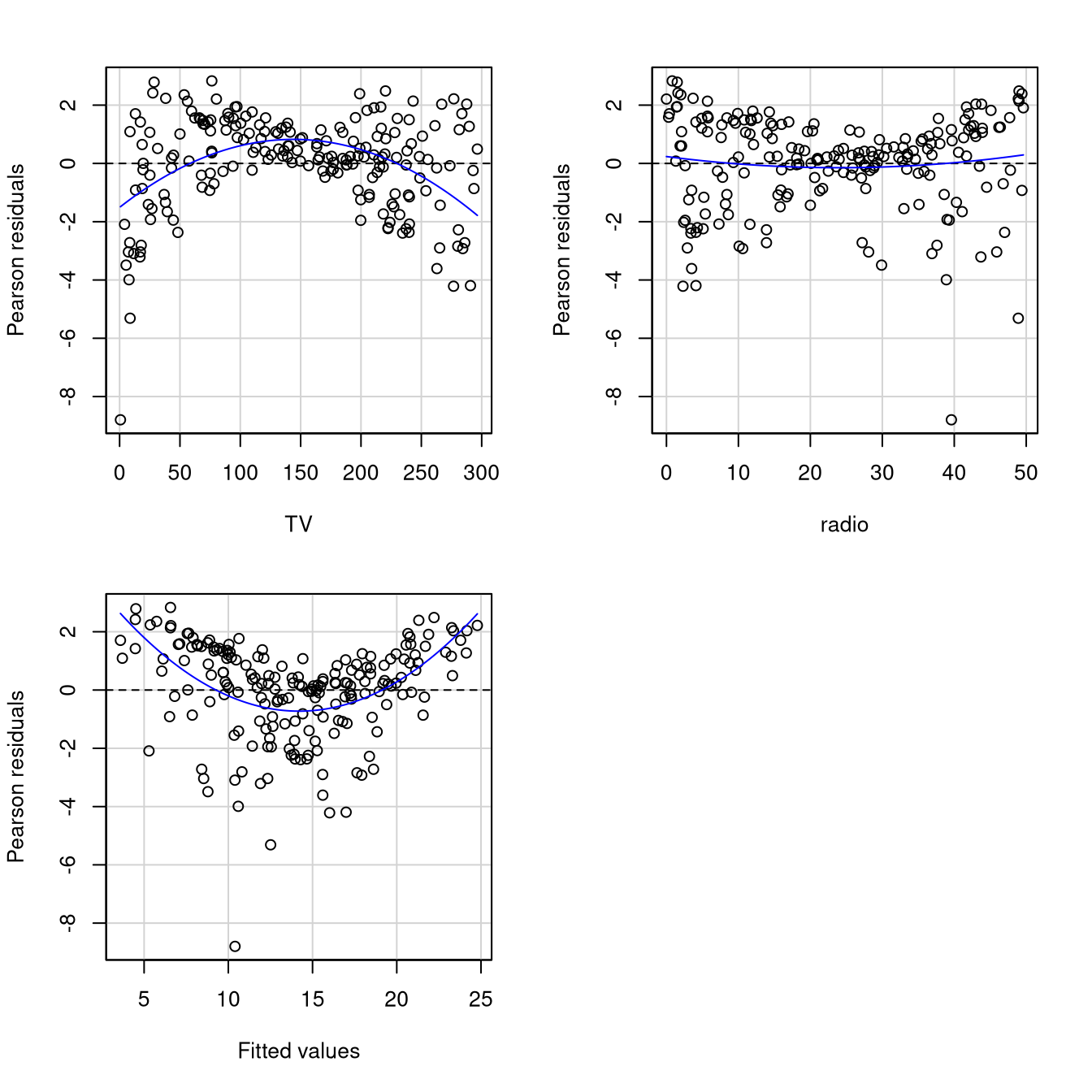
Diagnostic Plots
residualPlots(mod2)
Test stat Pr(>|Test stat|)
TV -6.7745 1.423e-10 ***
radio 1.0543 0.2931
Tukey test 7.6351 2.256e-14 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
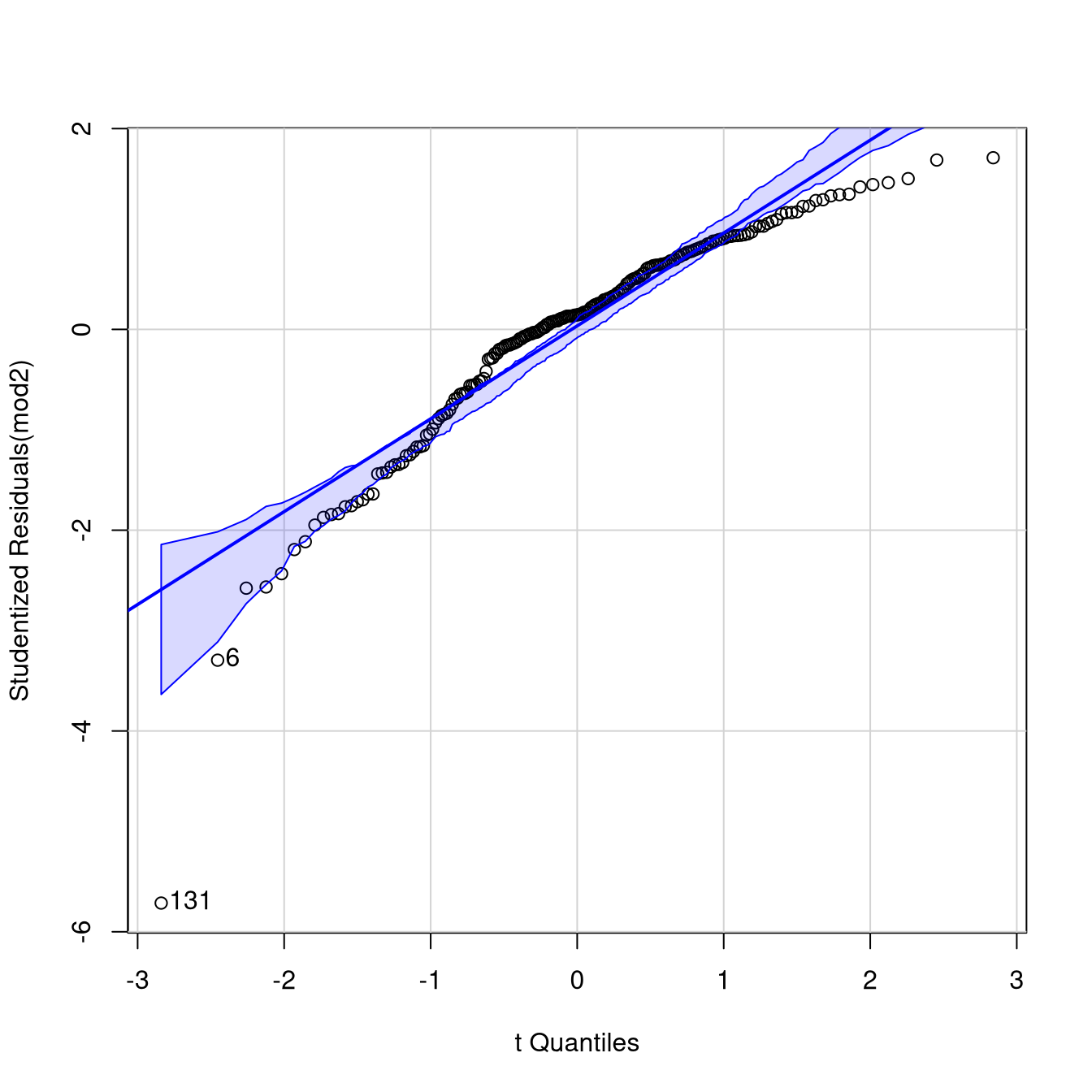
qqPlot(mod2)
[1] 6 131
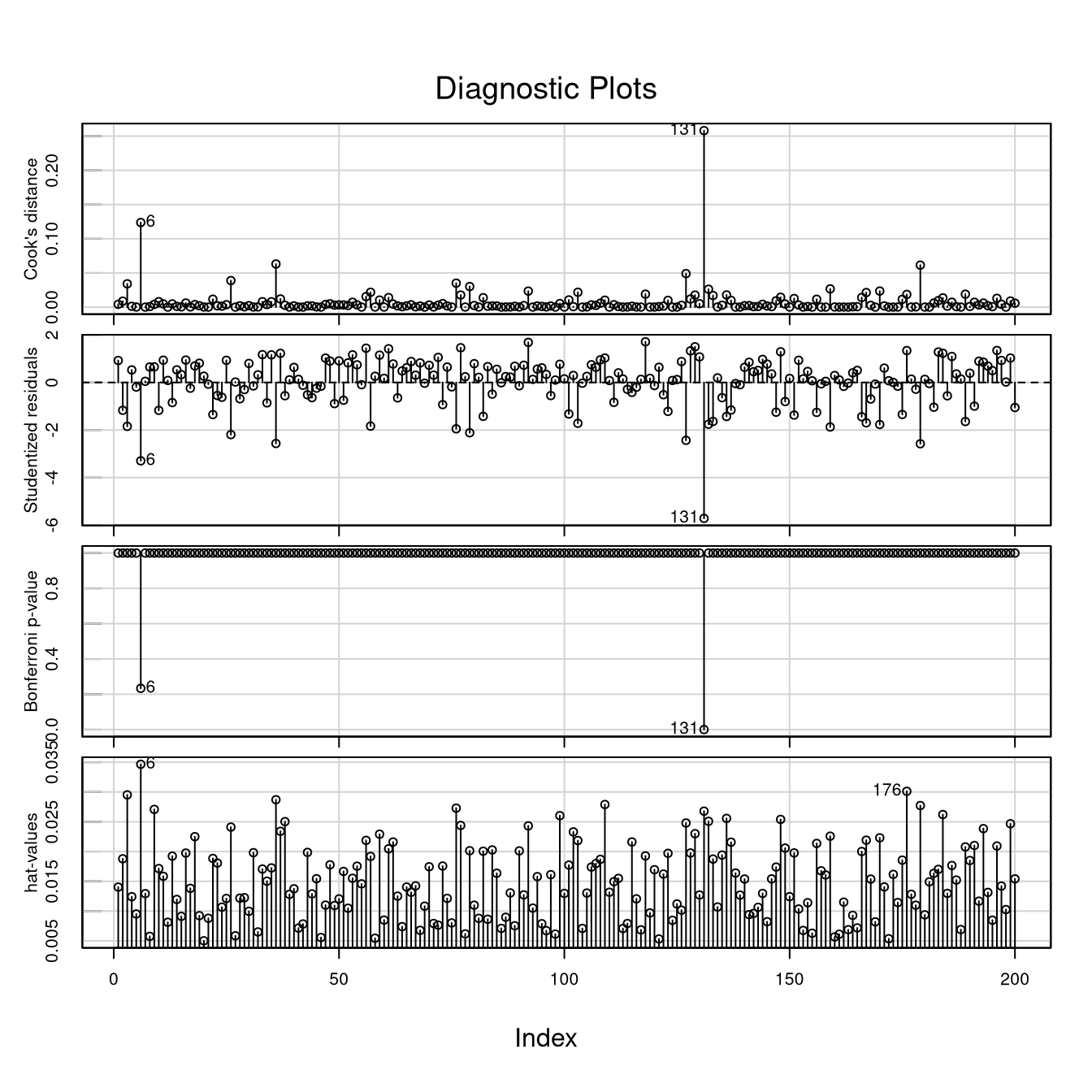
influenceIndexPlot(mod2)
We use a confidence interval to quantify the uncertainty surrounding the averagesales over a large number of cities. For example, given that $100,000 is spent on TV advertising and $20,000 is spent on Radio advertising in each city, the 95% confidence interval is [10.9852544, 11.5276775]. We interpret this to mean that 95% of intervals of this form will contain the true value of Sales.
predict(mod.be, newdata =data.frame(TV =100, radio =20), interval ="conf")
fit lwr upr
1 11.25647 10.98525 11.52768
On the other hand, a prediction interval can be used to quantify the uncertainty surrounding sales for a particular city. Given that $100,000 is spent on TV advertising and $20,000 is spent on radio advertising in a particular city, the 95% prediction interval is [7.9296161, 14.5833158]. We interpret this to mean that 95% of intervals of this form will contain the true value of Sales for this city.
predict(mod.be, newdata =data.frame(TV =100, radio =20), interval ="pred")
fit lwr upr
1 11.25647 7.929616 14.58332
Note that both the intervals are centered at 11.256466, but that the prediction interval is substantially wider than the confidence interval, reflecting the increased uncertainty about Sales for a given city in comparison to the average sales over many locations.
Non-Additive Models
nam1 <-lm(sales ~ TV*radio, data = AD)# Same as nam2 <-lm(sales ~ TV + radio + TV:radio, data = AD)summary(nam1)
Call:
lm(formula = sales ~ TV * radio, data = AD)
Residuals:
Min 1Q Median 3Q Max
-6.3366 -0.4028 0.1831 0.5948 1.5246
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 6.750e+00 2.479e-01 27.233 <2e-16 ***
TV 1.910e-02 1.504e-03 12.699 <2e-16 ***
radio 2.886e-02 8.905e-03 3.241 0.0014 **
TV:radio 1.086e-03 5.242e-05 20.727 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9435 on 196 degrees of freedom
Multiple R-squared: 0.9678, Adjusted R-squared: 0.9673
F-statistic: 1963 on 3 and 196 DF, p-value: < 2.2e-16
summary(nam2)
Call:
lm(formula = sales ~ TV + radio + TV:radio, data = AD)
Residuals:
Min 1Q Median 3Q Max
-6.3366 -0.4028 0.1831 0.5948 1.5246
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 6.750e+00 2.479e-01 27.233 <2e-16 ***
TV 1.910e-02 1.504e-03 12.699 <2e-16 ***
radio 2.886e-02 8.905e-03 3.241 0.0014 **
TV:radio 1.086e-03 5.242e-05 20.727 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9435 on 196 degrees of freedom
Multiple R-squared: 0.9678, Adjusted R-squared: 0.9673
F-statistic: 1963 on 3 and 196 DF, p-value: < 2.2e-16
Hierarchical Principle: If an interaction term is included in a model, one should also include the main effects, even if the p-values associated with their coefficients are not significant.
Qualitative Predictors
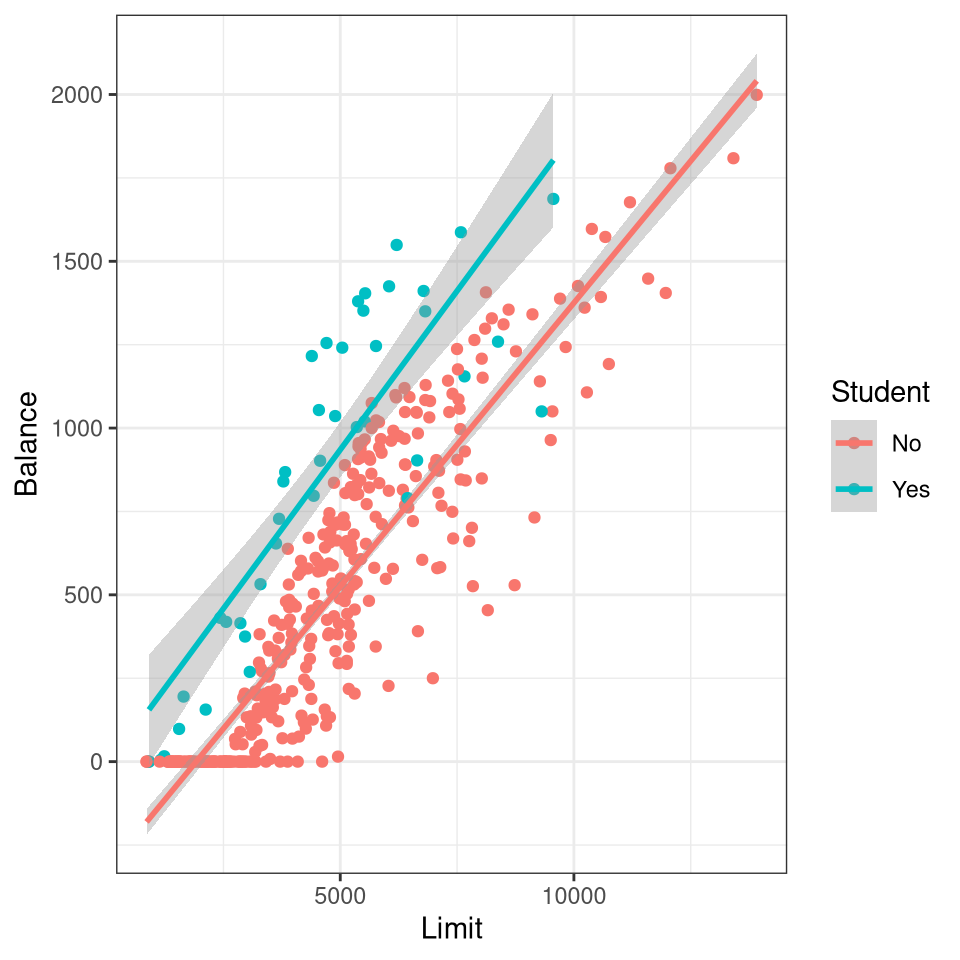
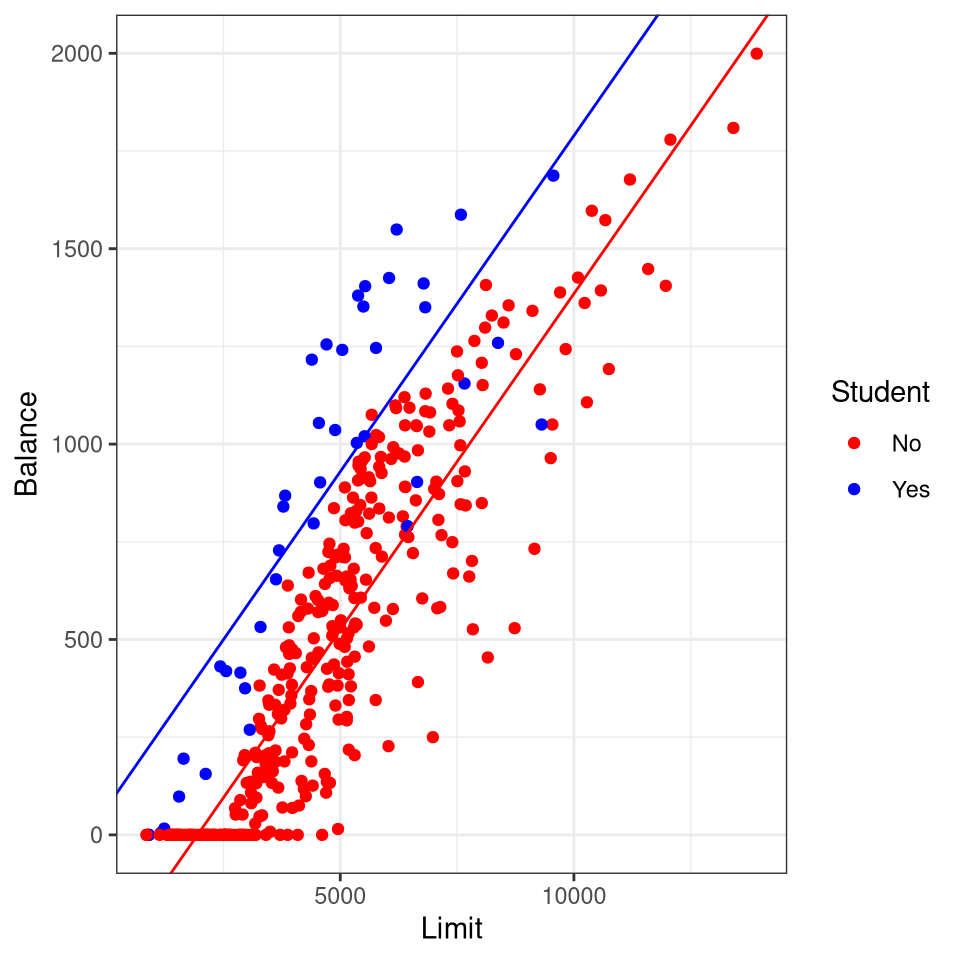
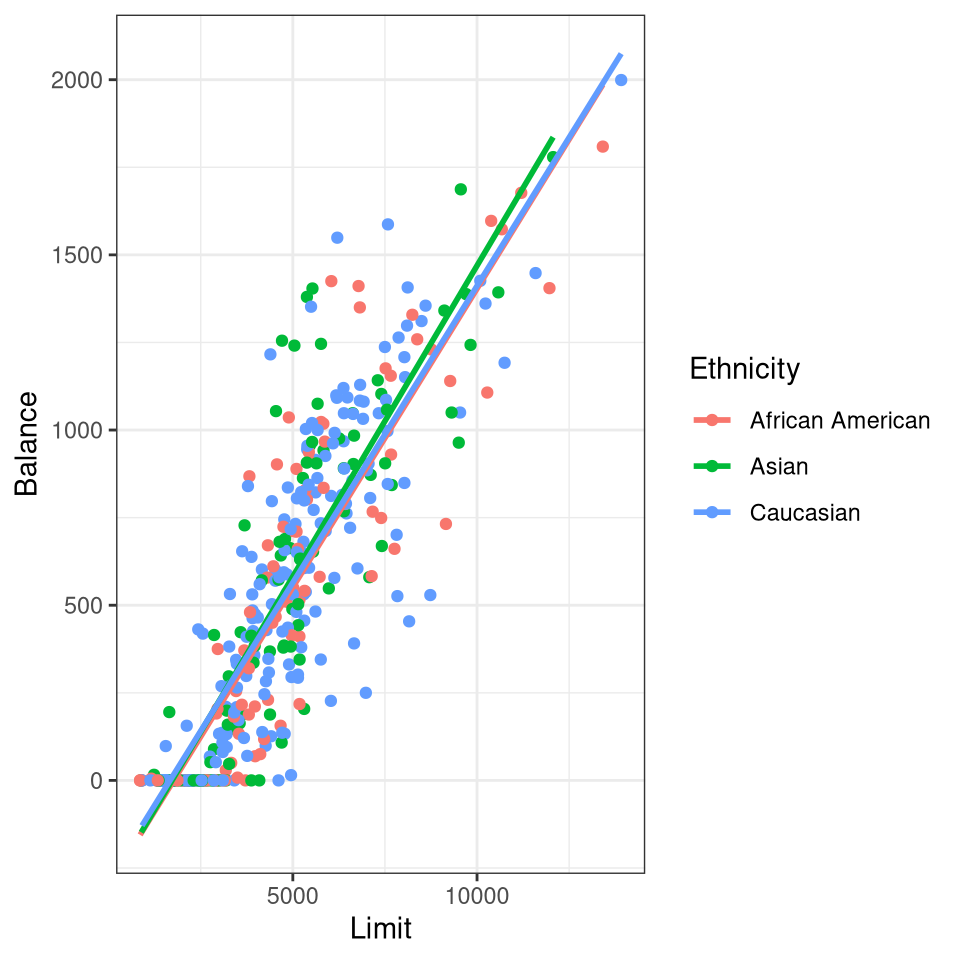
In the Credit data frame there are four qualitative features/variables Gender, Student, Married, and Ethnicity.
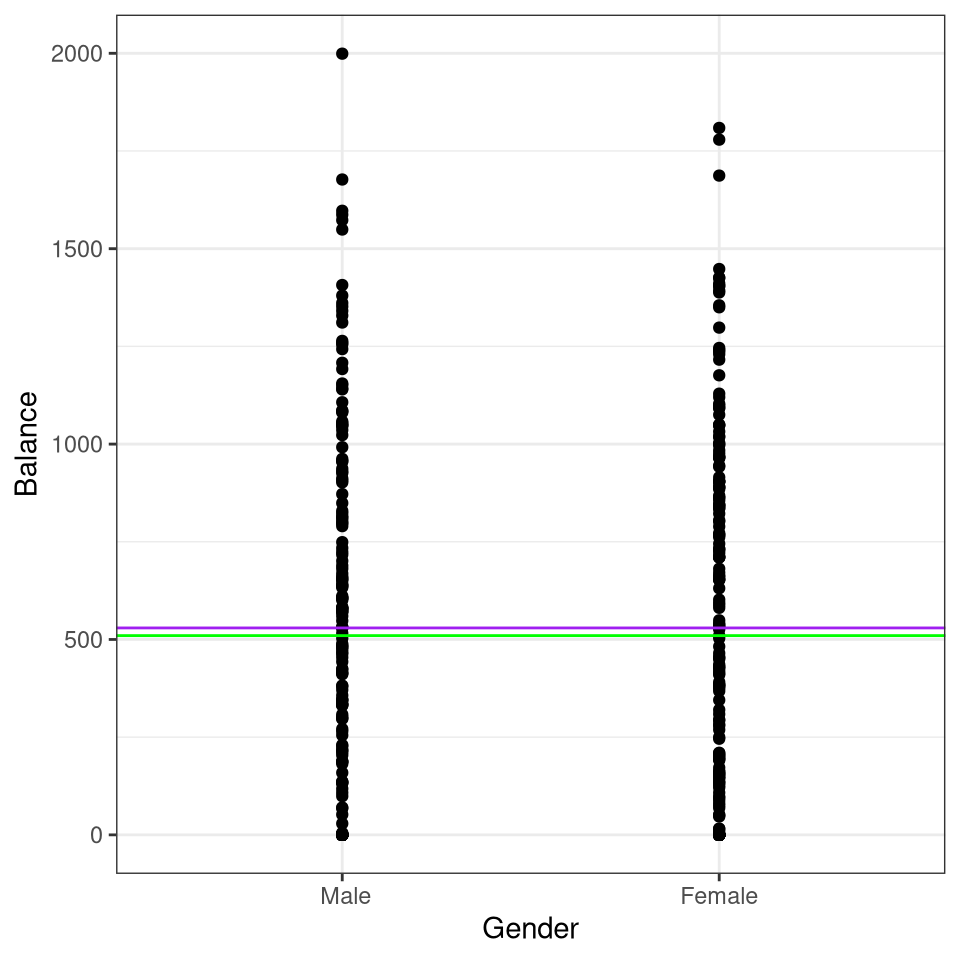
Suppose we wish to investigate differences in credit card balance between males and females, ignoring the other variables for the moment.
library(ISLR)data(Credit)modS <-lm(Balance ~ Gender, data = Credit)summary(modS)
Call:
lm(formula = Balance ~ Gender, data = Credit)
Residuals:
Min 1Q Median 3Q Max
-529.54 -455.35 -60.17 334.71 1489.20
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 509.80 33.13 15.389 <2e-16 ***
GenderFemale 19.73 46.05 0.429 0.669
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 460.2 on 398 degrees of freedom
Multiple R-squared: 0.0004611, Adjusted R-squared: -0.00205
F-statistic: 0.1836 on 1 and 398 DF, p-value: 0.6685
coef(modS)
(Intercept) GenderFemale
509.80311 19.73312
tapply(Credit$Balance, Credit$Gender, mean)
Male Female
509.8031 529.5362
library(ggplot2)ggplot(data = Credit, aes(x = Gender, y = Balance)) +geom_point() +theme_bw() +geom_hline(yintercept =coef(modS)[1] +coef(modS)[2], color ="purple") +geom_hline(yintercept =coef(modS)[1], color ="green")
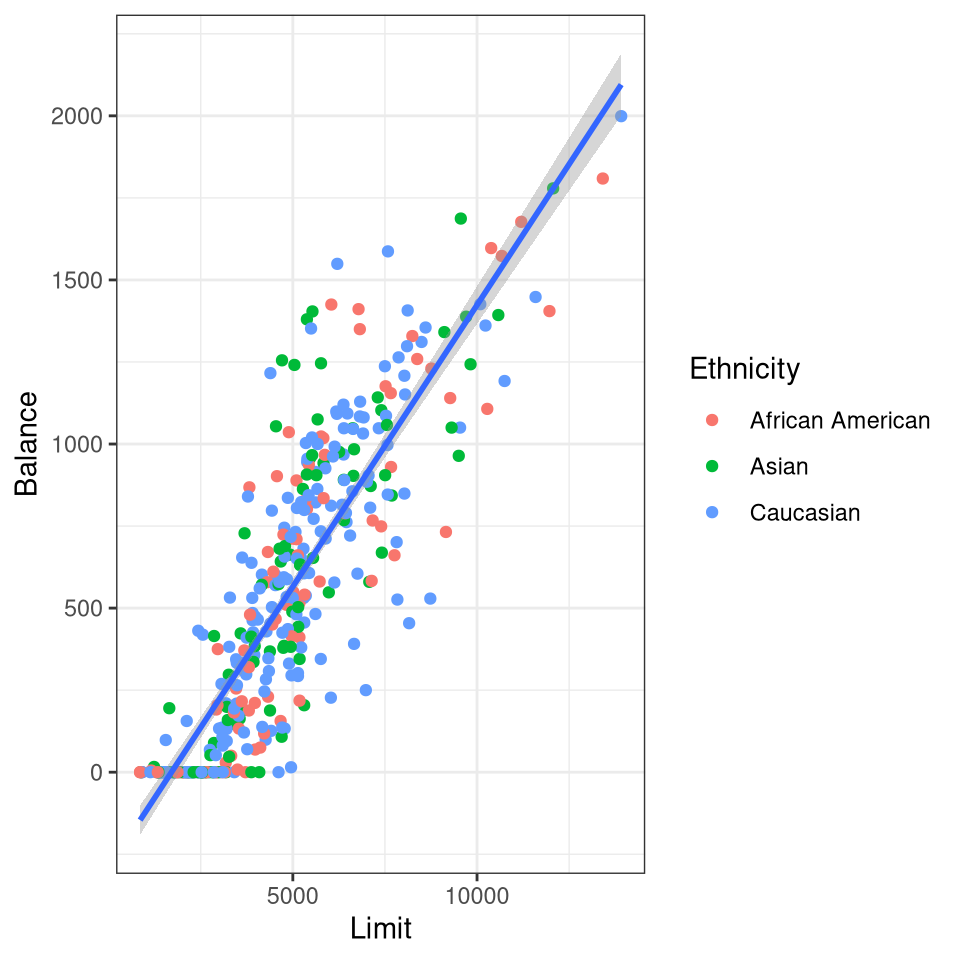
Do females have a higher ratio of Balance to Income (credit utilization)? Here is an article from the Washington Post with numbers that mirror some of the results in the Credit data set.
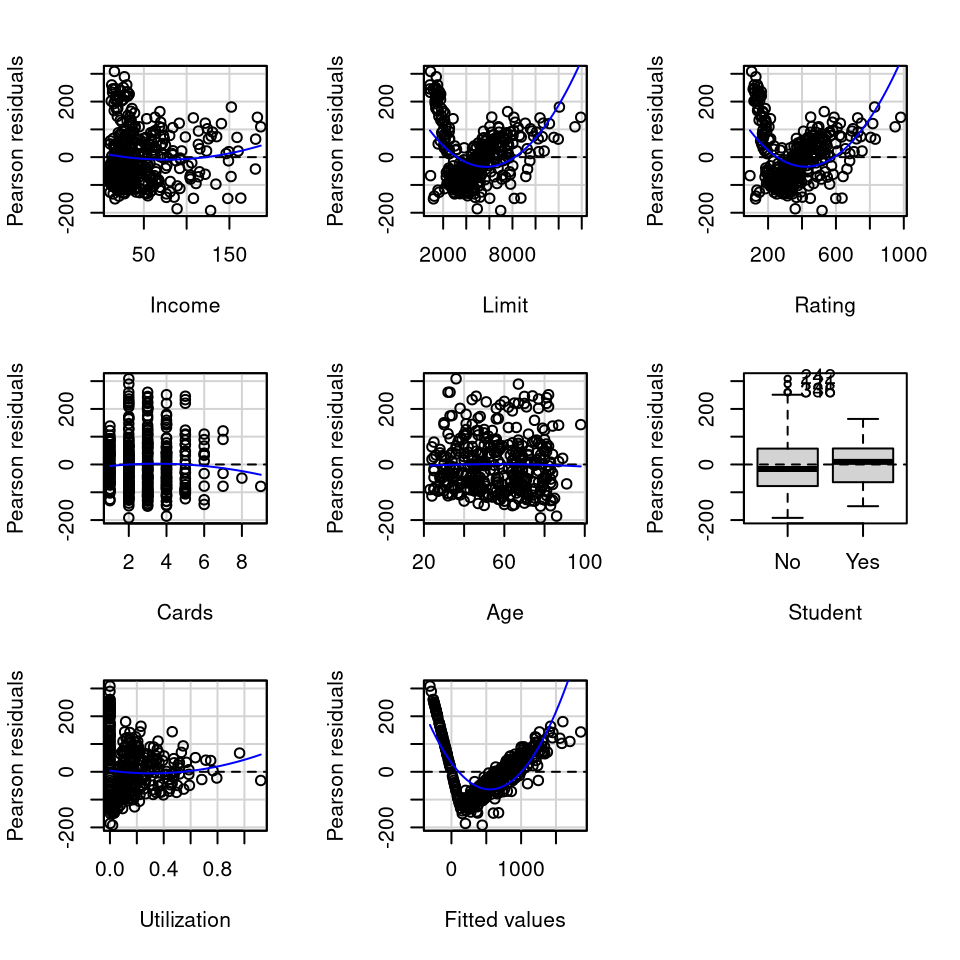
Test stat Pr(>|Test stat|)
Income 1.5431 0.1236
Limit 12.2615 <2e-16 ***
Rating 11.7689 <2e-16 ***
Cards -0.7709 0.4412
Age -0.2795 0.7800
Student
Utilization 1.4250 0.1550
Tukey test 25.9407 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
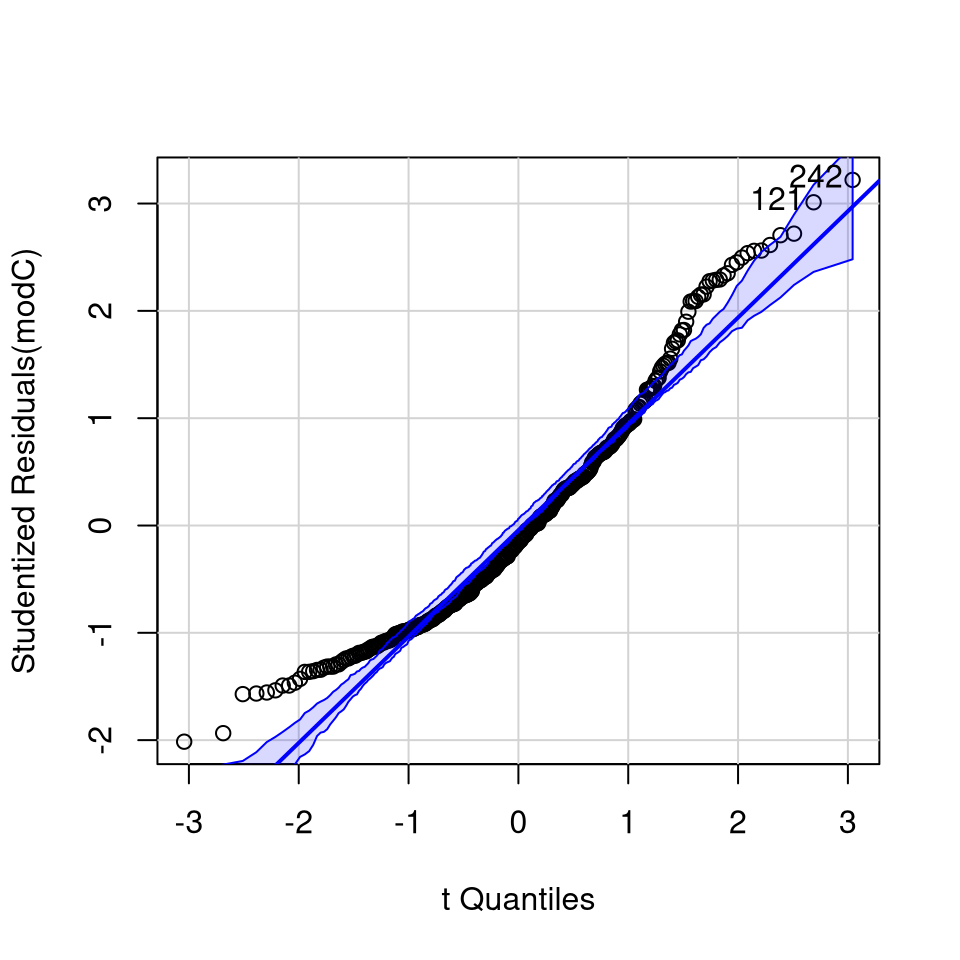
qqPlot(modC)
[1] 121 242
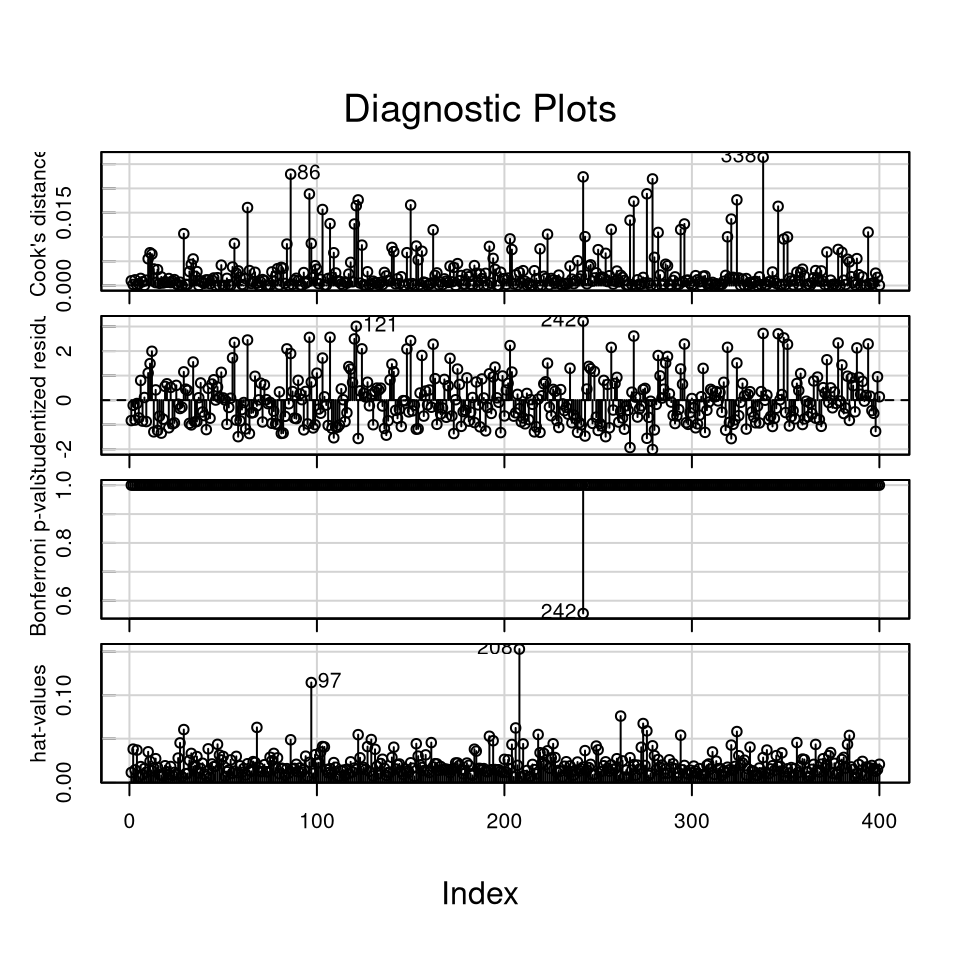
influenceIndexPlot(modC)
Non-linear Relationships
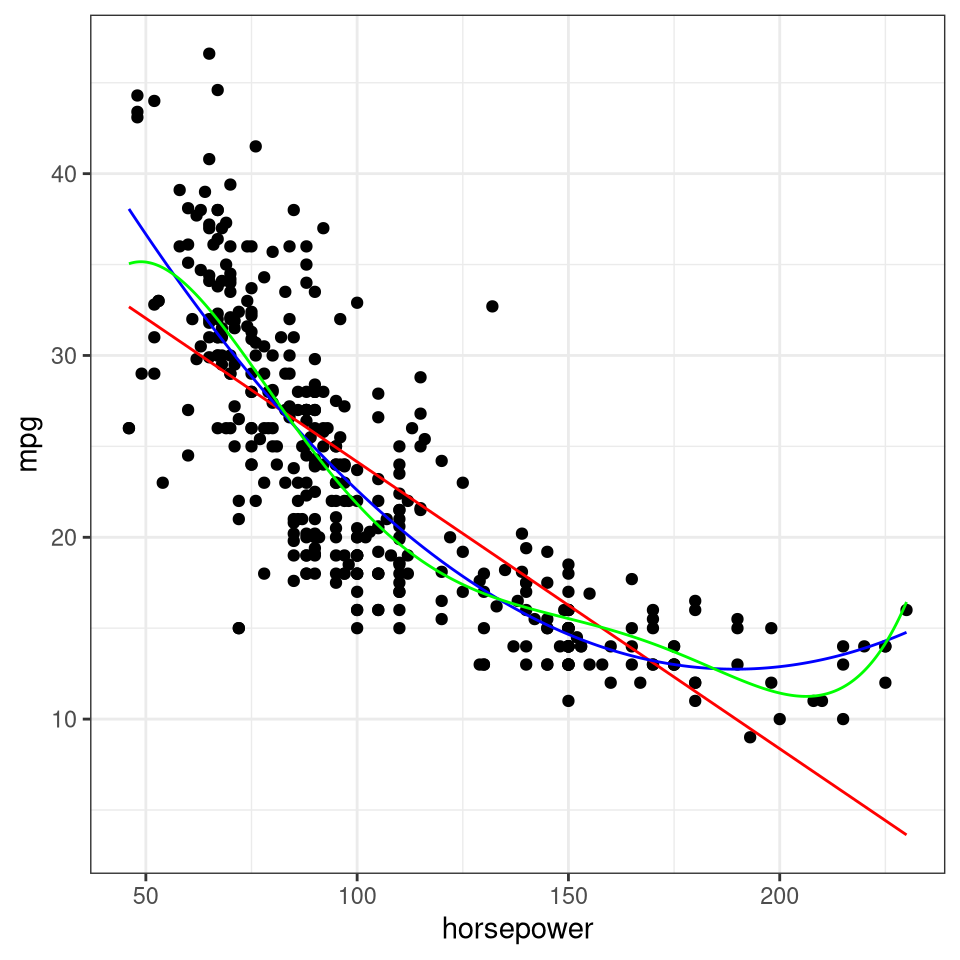
library(ISLR)car1 <-lm(mpg ~ horsepower, data = Auto)car2 <-lm(mpg ~poly(horsepower, 2), data = Auto)car5 <-lm(mpg ~poly(horsepower, 5), data = Auto)xs <-seq(min(Auto$horsepower), max(Auto$horsepower), length =500)y1 <-predict(car1, newdata =data.frame(horsepower = xs))y2 <-predict(car2, newdata =data.frame(horsepower = xs))y5 <-predict(car5, newdata =data.frame(horsepower = xs))DF <-data.frame(x = xs, y1 = y1, y2 = y2, y5 = y5)ggplot(data = Auto, aes(x = horsepower, y = mpg)) +geom_point() +theme_bw() +geom_line(data = DF, aes(x = x, y = y1), color ="red") +geom_line(data = DF, aes(x = x, y = y2), color ="blue") +geom_line(data = DF, aes(x = x, y = y5), color ="green")
Figure 8: Showing non-linear relationships
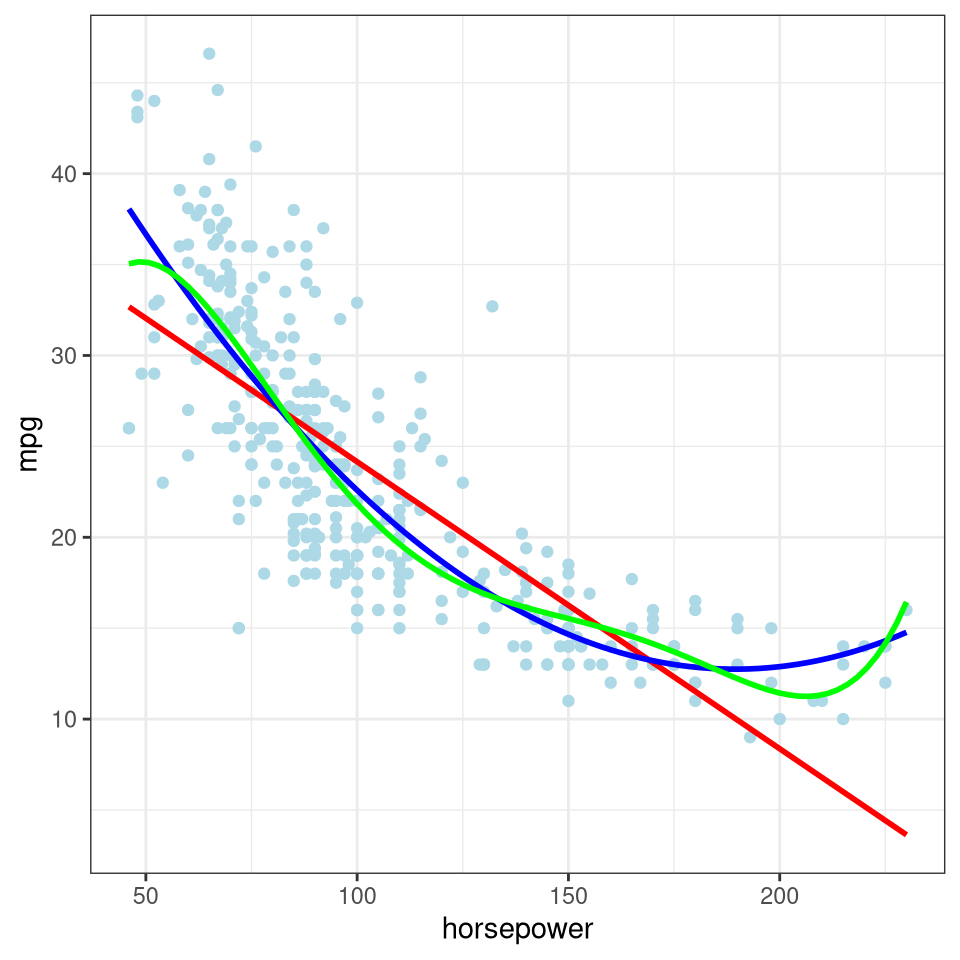
ggplot(data = Auto, aes(x = horsepower, y = mpg)) +geom_point(color ="lightblue") +theme_bw() +stat_smooth(method ="lm", data = Auto, color ="red", se =FALSE) +stat_smooth(method ="lm", formula = y ~poly(x, 2), data = Auto, color ="blue", se =FALSE) +stat_smooth(method ="lm", formula = y ~poly(x, 5), data = Auto, color ="green", se =FALSE)
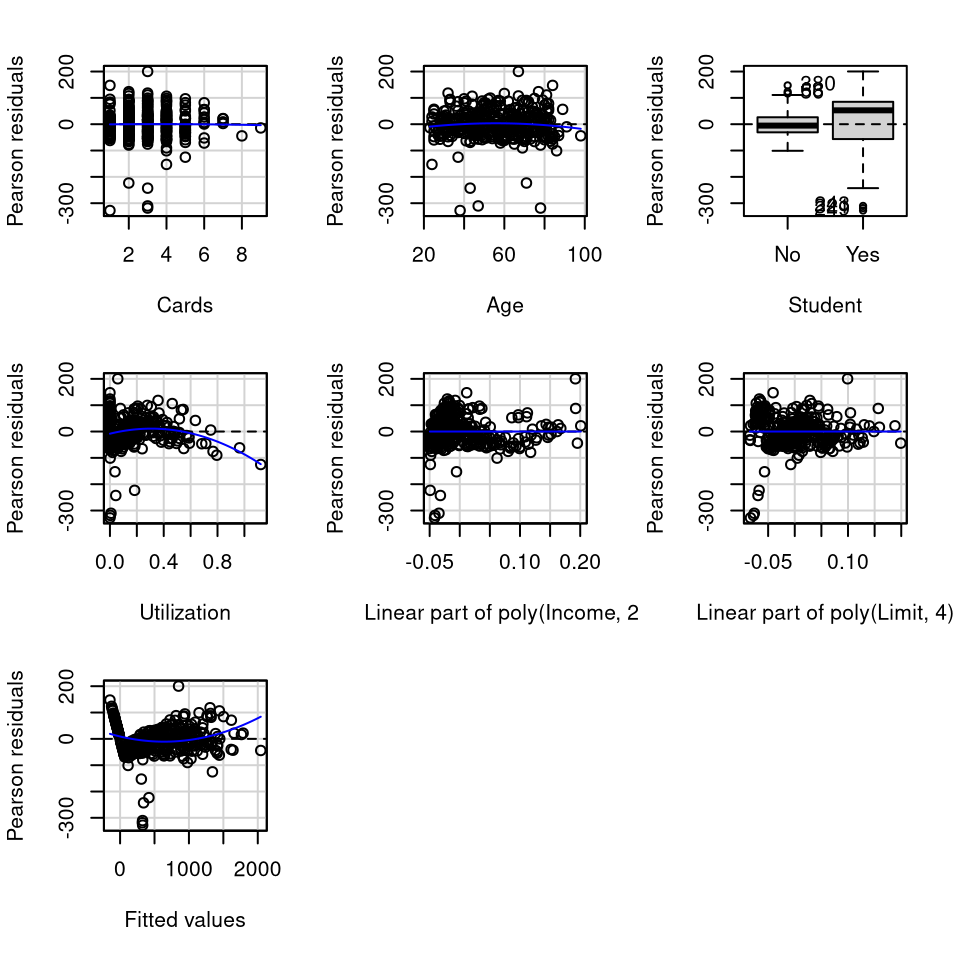
Test stat Pr(>|Test stat|)
Cards -0.1284 0.8979
Age -1.2123 0.2261
Student
Utilization -5.4273 1.010e-07 ***
poly(Income, 2)
poly(Limit, 4)
Tukey test 8.1970 2.465e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
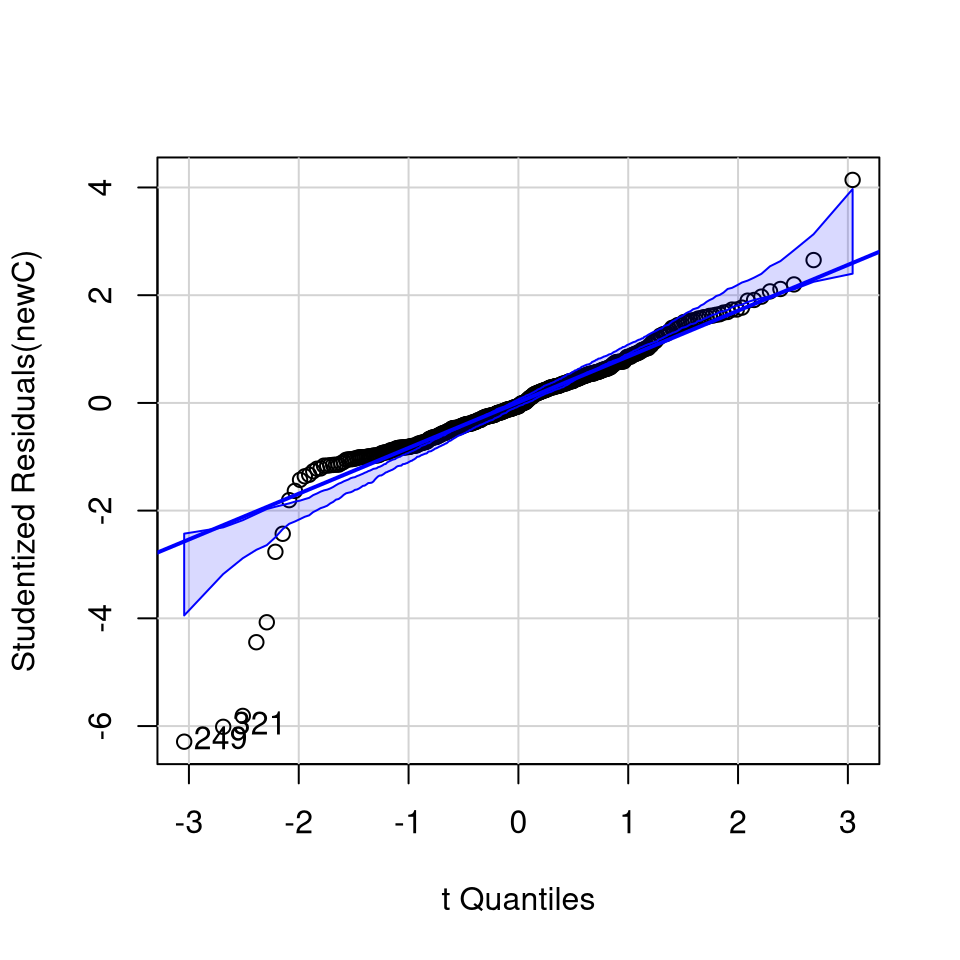
qqPlot(newC)
[1] 249 321
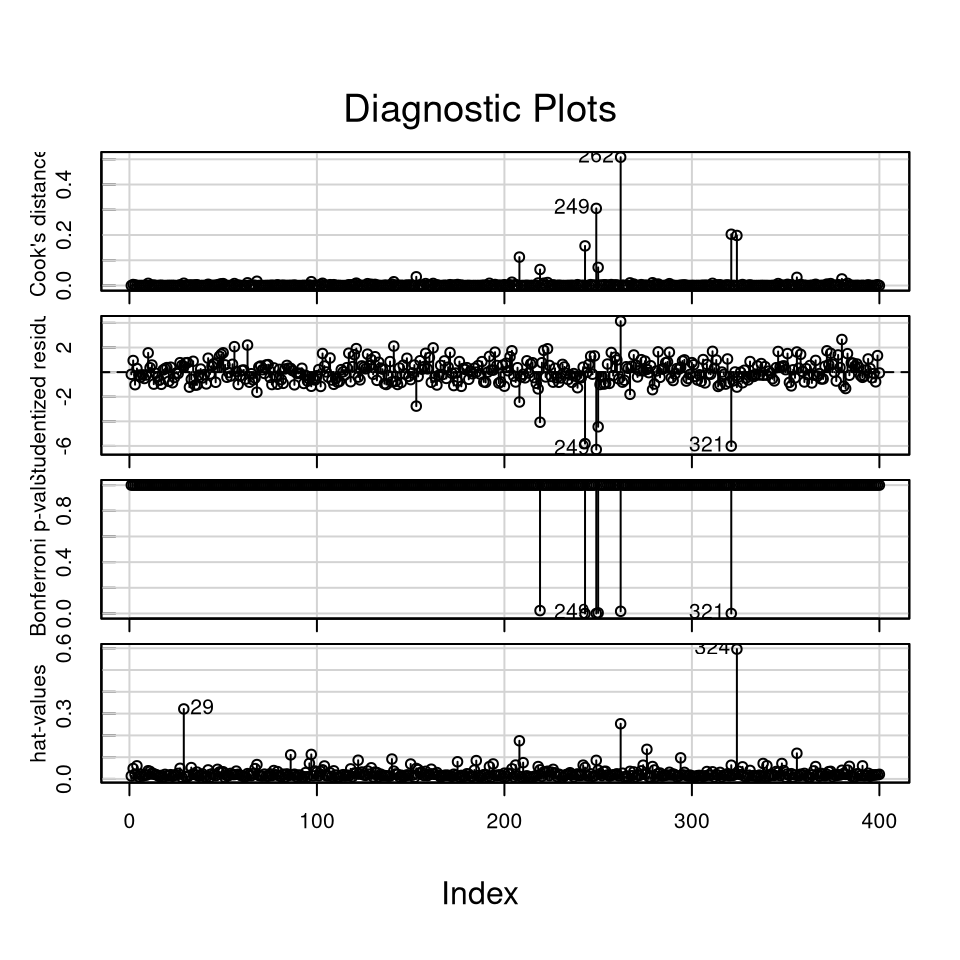
influenceIndexPlot(newC)
Variance Inflation Factor (VIF)
The VIF is the ratio of the variance of \(\hat{\beta}_j\) when fitting the full model divided by the variance of \(\hat{\beta}_j\) if it is fit on its own. The smallest possible value for VIF is 1, which indicates the complete absence of collinearity. The VIF for each variable can be computed using the formula:
where \(R^2_{X_j|X_{-j}}\) is the \(R^2\) from a regression of \(X_j\) onto all of the other predictors. If \(R^2_{X_j|X_{-j}}\) is close to one, then collinearity is present, and so the VIF will be large.
Compute the VIF for each \(\hat{\beta}_j\) of modC
modC
Call:
lm(formula = Balance ~ Income + Limit + Rating + Cards + Age +
Student + Utilization, data = Credit)
Coefficients:
(Intercept) Income Limit Rating Cards Age
-487.7563 -6.9234 0.1823 1.0649 16.3703 -0.5606
StudentYes Utilization
403.9969 145.4632
R2inc <-summary(lm(Income ~ Limit + Rating + Cards + Age + Student + Utilization, data = Credit))$r.squaredR2inc
[1] 0.8716908
VIFinc <-1/(1- R2inc)VIFinc
[1] 7.793671
R2lim <-summary(lm(Limit ~ Income + Rating + Cards + Age + Student + Utilization, data = Credit))$r.squaredR2lim
[1] 0.9957067
VIFlim <-1/(1- R2lim)VIFlim
[1] 232.9193
This is tedious is there a function to do this? Yes!
car::vif(modC)
Income Limit Rating Cards Age Student
7.793671 232.919318 230.957276 1.472901 1.046060 1.233070
Utilization
3.323397
Exercise
Create a model that predicts an individuals credit rating (Rating).
Create another model that predicts rating with Limit, Cards, Married, Student, and Education as features.
Use your model to predict the Rating for an individual who has a credit card limit of $6,000, has 4 credit cards, is married, is not a student, and has an undergraduate degree (Education = 16).
Use your model to predict the Rating for an individual who has a credit card limit of $12,000, has 2 credit cards, is married, is not a student, and has an eighth grade education (Education = 8).