Last modified on August 15, 2023 10:17:53 Eastern Daylight Time
Data
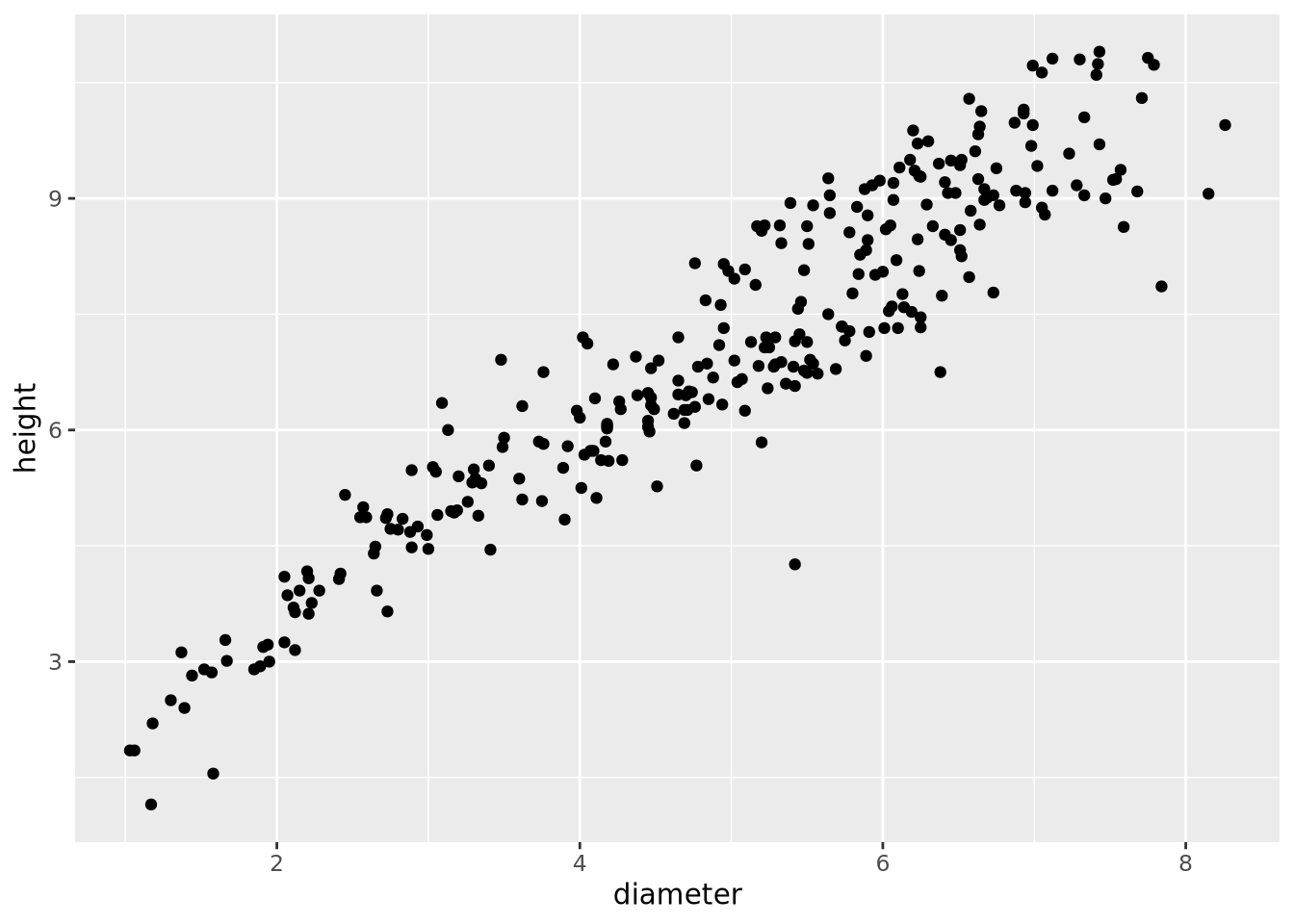
This section presents a data set that shows how different data types should be read into R as well as several functions that are useful for working with different types of R objects. Consider the data stored as a CSV file at
The following description of the data is from Minitab 15:
MINITAB
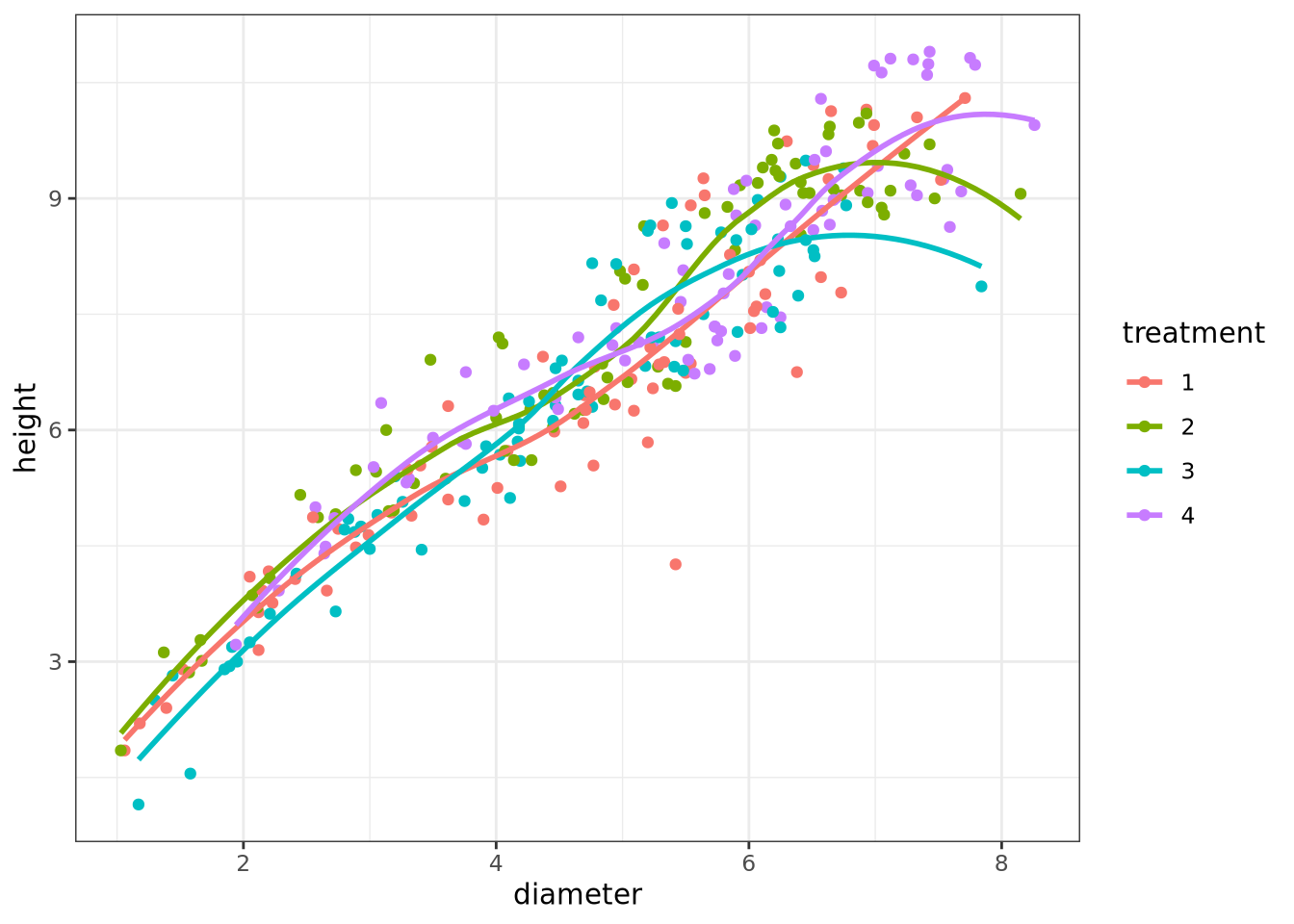
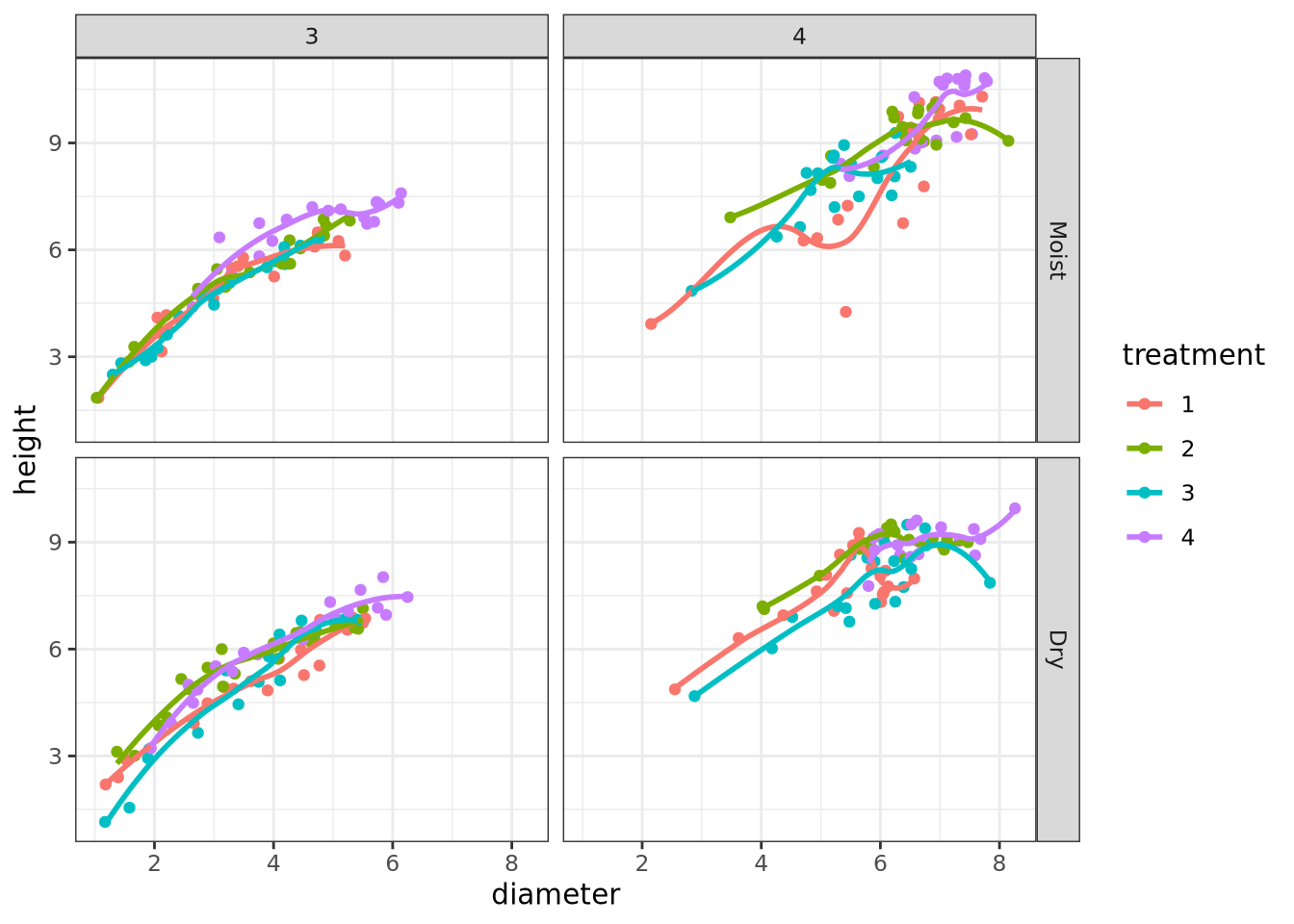
In an effort to maximize yield, researchers designed an experiment to determine how two factors, Site and Treatment, influence the Weight of four-year-old poplar clones. They planted trees on two sites: Site 1 is a moist site with rich soil, and Site 2 is a dry, sandy site. They applied four different treatments to the trees: Treatment 1 was the control (no treatment); Treatment 2 used fertilizer; Treatment 3 used irrigation; and Treatment 4 use both fertilizer and irrigation. To account for a variety of weather conditions, the researchers replicated the data by planting half the trees in Year 1, and the other half in Year 2.
Base R
The data from Poplar3.CSV is read into the data frame poplar using the read.csv() function, and the first five rows of the data frame are shown using the function head() with the argument n = 5 to show the first five rows of the data frame instead of the default n = 6 rows.
R Code
site <-"https://raw.githubusercontent.com/alanarnholt/Data/master/POPLAR3.CSV"poplar <-read.csv(file =url(site))knitr::kable(head(poplar, n =5)) # show first five rows
site
year
treatment
diameter
height
weight
age
1
1
1
2.23
3.76
0.17
3
1
1
1
2.12
3.15
0.15
3
1
1
1
1.06
1.85
0.02
3
1
1
1
2.12
3.64
0.16
3
1
1
1
2.99
4.64
0.37
3
When dealing with imported data sets, it is always good to examine their contents using functions such as str() and summary(), which show the structure and provide appropriate summaries, respectively, for different types of objects.
R Code
str(poplar)
'data.frame': 298 obs. of 7 variables:
$ site : int 1 1 1 1 1 1 1 1 1 2 ...
$ year : int 1 1 1 1 1 1 1 1 1 1 ...
$ treatment: int 1 1 1 1 1 1 1 1 1 1 ...
$ diameter : num 2.23 2.12 1.06 2.12 2.99 4.01 2.41 2.75 2.2 4.09 ...
$ height : num 3.76 3.15 1.85 3.64 4.64 5.25 4.07 4.72 4.17 5.73 ...
$ weight : num 0.17 0.15 0.02 0.16 0.37 0.73 0.22 0.3 0.19 0.78 ...
$ age : int 3 3 3 3 3 3 3 3 3 3 ...
summary(poplar)
site year treatment diameter
Min. :1.00 Min. :1.00 Min. :1.000 Min. :-99.000
1st Qu.:1.00 1st Qu.:1.00 1st Qu.:2.000 1st Qu.: 3.605
Median :2.00 Median :2.00 Median :2.500 Median : 5.175
Mean :1.51 Mean :1.51 Mean :2.503 Mean : 3.862
3rd Qu.:2.00 3rd Qu.:2.00 3rd Qu.:3.750 3rd Qu.: 6.230
Max. :2.00 Max. :2.00 Max. :4.000 Max. : 8.260
height weight age
Min. :-99.000 Min. :-99.000 Min. :3.000
1st Qu.: 5.495 1st Qu.: 0.605 1st Qu.:3.000
Median : 6.910 Median : 1.640 Median :4.000
Mean : 5.902 Mean : 1.099 Mean :3.507
3rd Qu.: 8.750 3rd Qu.: 3.435 3rd Qu.:4.000
Max. : 10.900 Max. : 6.930 Max. :4.000
From typing str(poplar) at the R prompt, one can see that all seven variables are either integer or numeric. From the description, the variables Site and Treatment are factors. Further investigation into the experiment reveals that year and Age are factors as well. Recall that factors are an extension of vectors designed for storing categorical information. The results of summary(poplar) indicate the minimum values for Diameter, Height, and Weight are all -99, which does not make sense unless one is told that a value of -99 for these variables represents a missing value. Once one understands that the variables Site, Year, Treatment, and Age are factors and that the value -99 has been used to represent missing values for the variables Diameter, Height, and Weight, appropriate arguments to read.csv() can be entered. The data is now read into the object poplarC using na.strings = "-99" to store the NA values correctly. The argument colClasses= requires a vector that indicates the desired class of each column.
In the event different values (999, 99, 9999) for different variables (var1, var2, var3) are used to represent missing values in a data set, the argument na.strings= will no longer be able to solve the problem directly. Although one can pass a vector of the form na.strings = c(999, 99, 9999), this will simply replace all values that are 999, 99, or 9999 with NAs. If the first variable has a legitimate value of 99, then it too would be replaced with an NA value. One solution for this problem in general is to read the data set into a data frame (DF), to assign the data frame to a different name so that the cleaned up data set is not confused with the original data, and to use filtering to assign NAs to values of var1, var2, and var3 that have entries of 999, 99, and 999, respectively.
Once a variable has its class changed from int to factor, labeling the levels of the factor can be accomplished without difficulties. To facilitate analysis of the poplarC data, labels for the levels of the variables Site and Treatment are assigned.
site year treatment diameter
Min. :1.00 Min. :1.00 Min. :1.000 Min. :-99.000
1st Qu.:1.00 1st Qu.:1.00 1st Qu.:2.000 1st Qu.: 3.605
Median :2.00 Median :2.00 Median :2.500 Median : 5.175
Mean :1.51 Mean :1.51 Mean :2.503 Mean : 3.862
3rd Qu.:2.00 3rd Qu.:2.00 3rd Qu.:3.750 3rd Qu.: 6.230
Max. :2.00 Max. :2.00 Max. :4.000 Max. : 8.260
height weight age
Min. :-99.000 Min. :-99.000 Min. :3.000
1st Qu.: 5.495 1st Qu.: 0.605 1st Qu.:3.000
Median : 6.910 Median : 1.640 Median :4.000
Mean : 5.902 Mean : 1.099 Mean :3.507
3rd Qu.: 8.750 3rd Qu.: 3.435 3rd Qu.:4.000
Max. : 10.900 Max. : 6.930 Max. :4.000
#poplarR1 <-read_csv(file =url(site), na ="-99")summary(poplarR1)
site year treatment diameter height
Min. :1.00 Min. :1.00 Min. :1.000 Min. :1.030 Min. : 1.150
1st Qu.:1.00 1st Qu.:1.00 1st Qu.:2.000 1st Qu.:3.675 1st Qu.: 5.530
Median :2.00 Median :2.00 Median :2.500 Median :5.200 Median : 6.950
Mean :1.51 Mean :1.51 Mean :2.503 Mean :4.909 Mean : 6.969
3rd Qu.:2.00 3rd Qu.:2.00 3rd Qu.:3.750 3rd Qu.:6.235 3rd Qu.: 8.785
Max. :2.00 Max. :2.00 Max. :4.000 Max. :8.260 Max. :10.900
NA's :3 NA's :3
weight age
Min. :0.010 Min. :3.000
1st Qu.:0.635 1st Qu.:3.000
Median :1.680 Median :4.000
Mean :2.117 Mean :3.507
3rd Qu.:3.470 3rd Qu.:4.000
Max. :6.930 Max. :4.000
NA's :3
Classes 'data.table' and 'data.frame': 298 obs. of 7 variables:
$ site : int 1 1 1 1 1 1 1 1 1 2 ...
$ year : int 1 1 1 1 1 1 1 1 1 1 ...
$ treatment: int 1 1 1 1 1 1 1 1 1 1 ...
$ diameter : num 2.23 2.12 1.06 2.12 2.99 4.01 2.41 2.75 2.2 4.09 ...
$ height : num 3.76 3.15 1.85 3.64 4.64 5.25 4.07 4.72 4.17 5.73 ...
$ weight : num 0.17 0.15 0.02 0.16 0.37 0.73 0.22 0.3 0.19 0.78 ...
$ age : int 3 3 3 3 3 3 3 3 3 3 ...
- attr(*, ".internal.selfref")=<externalptr>
summary(poplarF)
site year treatment diameter height
Min. :1.00 Min. :1.00 Min. :1.000 Min. :1.030 Min. : 1.150
1st Qu.:1.00 1st Qu.:1.00 1st Qu.:2.000 1st Qu.:3.675 1st Qu.: 5.530
Median :2.00 Median :2.00 Median :2.500 Median :5.200 Median : 6.950
Mean :1.51 Mean :1.51 Mean :2.503 Mean :4.909 Mean : 6.969
3rd Qu.:2.00 3rd Qu.:2.00 3rd Qu.:3.750 3rd Qu.:6.235 3rd Qu.: 8.785
Max. :2.00 Max. :2.00 Max. :4.000 Max. :8.260 Max. :10.900
NA's :3 NA's :3
weight age
Min. :0.010 Min. :3.000
1st Qu.:0.635 1st Qu.:3.000
Median :1.680 Median :4.000
Mean :2.117 Mean :3.507
3rd Qu.:3.470 3rd Qu.:4.000
Max. :6.930 Max. :4.000
NA's :3